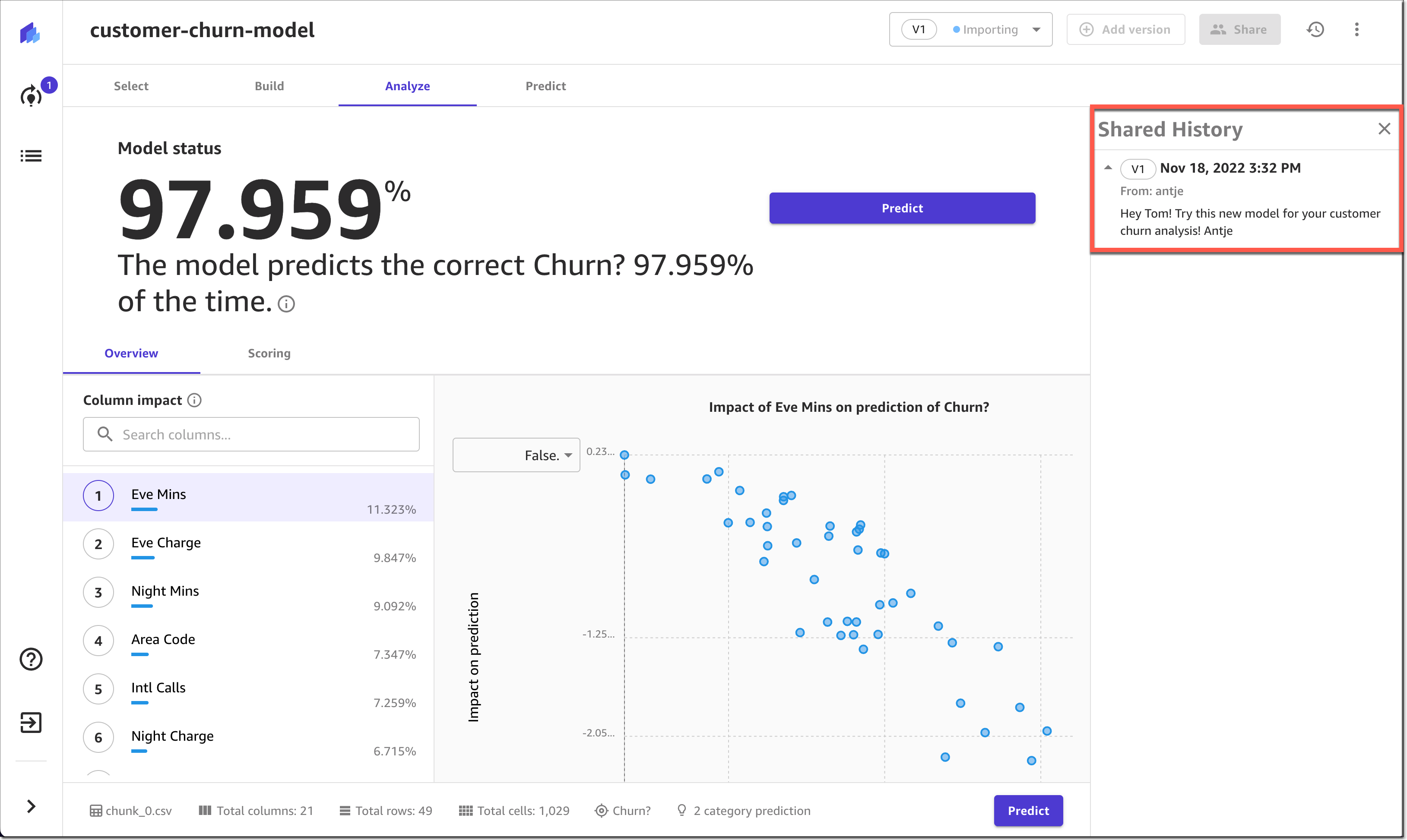
We are half way between the re:Invent conference and the end-of-year holidays, and I did expect the cadence of releases and news to slow down a bit, but nothing is further away from reality. Our teams continue to listen to your feedback and release new capabilities and incremental improvements.
This week, many items caught my attention. Here is my summary.
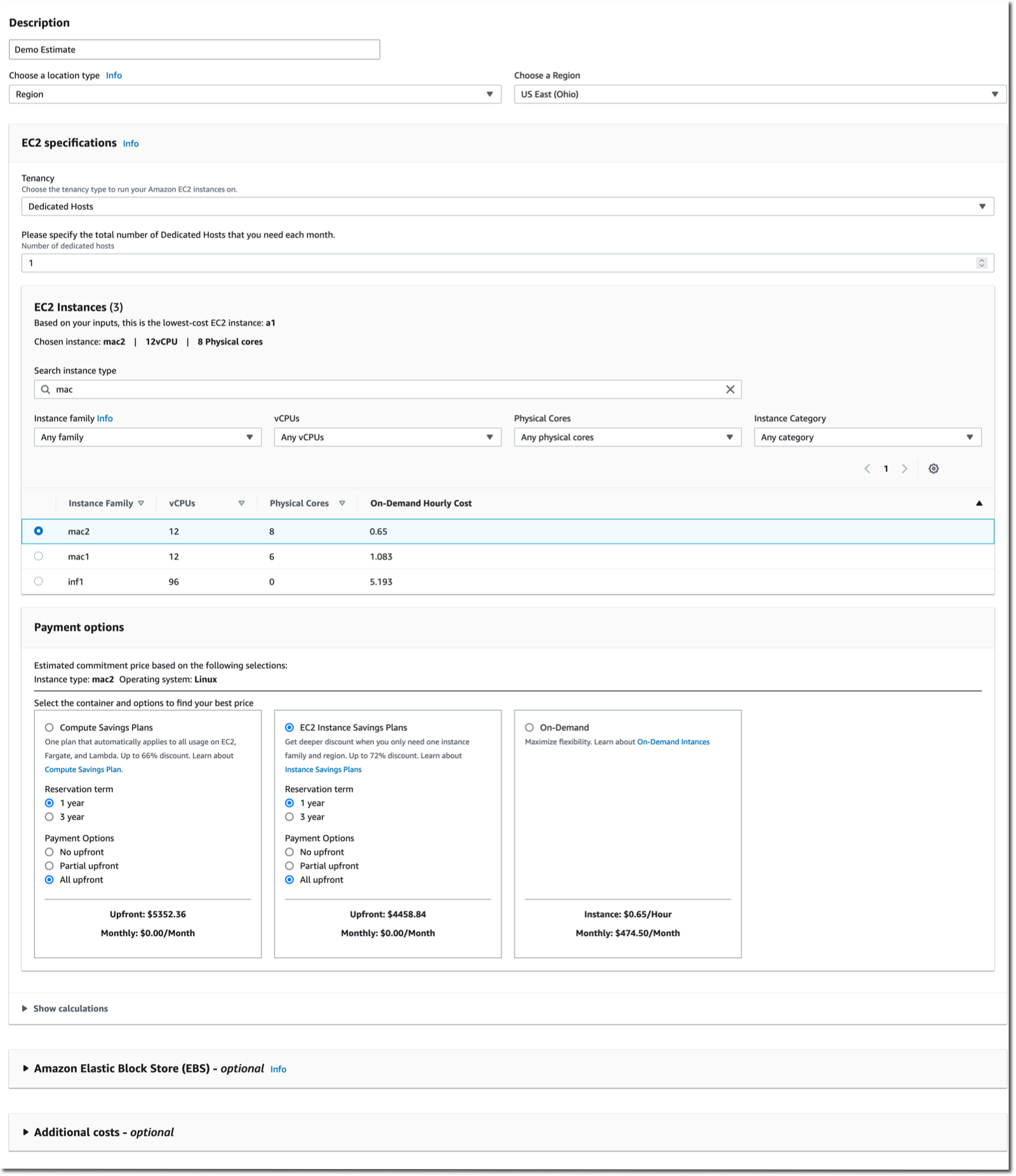
The AWS Pricing Calculator for Amazon EC2 is getting a redesign to provide you with a simplified, consistent, and efficient calculator to estimate costs. It also added a way to bulk estimate costs for EC2 instances, EC2 Dedicated Hosts, and Amazon EBS services. Try it for yourself today.
Amazon CloudWatch Metrics Insights alarms now enables you to trigger alarms on entire fleets of dynamically changing resources (such as automatically scaling EC2 instances) with a single alarm using standard SQL queries. For example, you can now write a query like this to collect data about CPU utilization over your entire dynamic fleet of EC2 instances.
SELECT AVG(CPUUtilization) FROM SCHEMA("AWS/EC2", InstanceId)AWS Amplify is a command line tool and a set of libraries to help you to build web and mobile applications connected to a cloud backend. We released Amplify Library for Android 2.0, with improvements and simplifications for user authentication. The team also released Amplify JavaScript library version 5, with improvements for React and React Native developers, such as a new notifications channel, also known as in-app messaging, that developers can use to display contextual messages to their users based on their behavior. The Amplify JavaScript library has also received improvements to reduce the overall bundle size and installation size.
Amazon Connect added granular access control based on resource tags for routing profiles, security profiles, users, and queues. It also adds bulk import for user hierarchy tags. This allows you to use attribute-based access control policies for Amazon Connect resources.
Amazon RDS Proxy now supports PostgreSQL major version 14. RDS Proxy is a fully managed, highly available database proxy for Amazon Relational Database Service (Amazon RDS) that makes applications more scalable, more resilient to database failures, and more secure. It is typically used by serverless applications that can have a large number of open connections to the database server and may open and close database connections at a high rate, exhausting database memory and compute resources.
AWS Gateway Load Balancer endpoints now support Ipv6 addresses. You can now send IPv6 traffic through Gateway Load Balancers and its endpoints to distribute traffic flows to dual stack appliance targets.
Amazon Location Service now provides Open Data Maps maps, in addition to ESRI and Here maps. I also noticed that Amazon is a core member of the new Overture Maps Foundation, officially hosted by the Linux Foundation. The mission of the Overture Maps Foundation is to power new map products through openly available datasets that can be used and reused across applications and businesses. The program is driven by Amazon Web Services (AWS), Facebook’s parent company Meta, Microsoft, and Dutch mapping company TomTom.
AWS Mainframe Modernization is a set of managed tools providing infrastructure and software for migrating, modernizing, and running mainframe applications. It is now available in three additional AWS Regions and supports AWS CloudFormation, AWS PrivateLink, AWS Key Management Service.
X in Y. Jeff started this section a while ago to list the expansion of new services and capabilities to additional Regions. I noticed 11 Regional expansions this week:
- Amazon AppStream 2.0 is now available in the South America (São Paulo) Region
- Amazon Neptune Serverless is now available in 5 additional AWS Regions
- Amazon Location Service now available in Asia Pacific (Mumbai), Canada (Central), Europe (London), and South America (São Paulo)
- Amazon Elastic File System (Amazon EFS) is now available in the AWS Europe (Zurich) Region
- Amazon QuickSight is now available in Stockholm and Paris Regions
- Amazon EC2 C6id, M6id, and R6id on one side, and M6a and C6a on the other side are now available in more Regions
- Amazon Kendra now available in Asia-Pacific (Mumbai) AWS Region
- Amazon MQ is now available in the Middle East (UAE) Region
- Contact Lens for Amazon Connect now provides conversational analytics in Africa (Cape Town) Region
- Amazon ECS Service Connect now available in the AWS China (Beijing) and AWS China (Ningxia) Regions
- Amazon GuardDuty now available in AWS Europe (Zurich) Region
Other AWS News
This week, I also noticed these AWS news items:
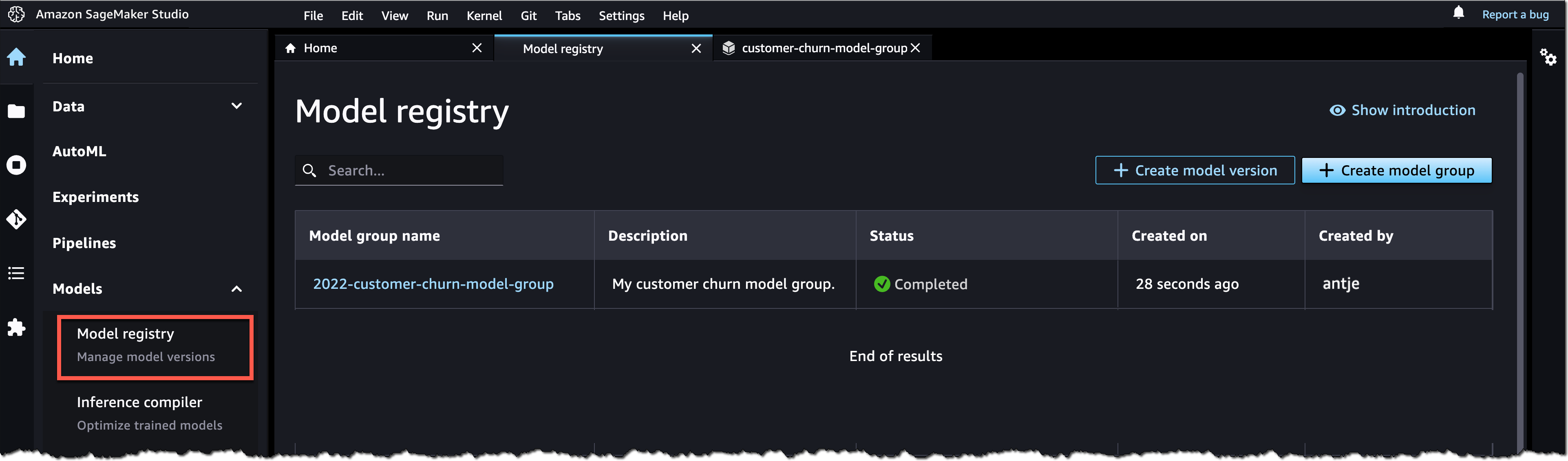
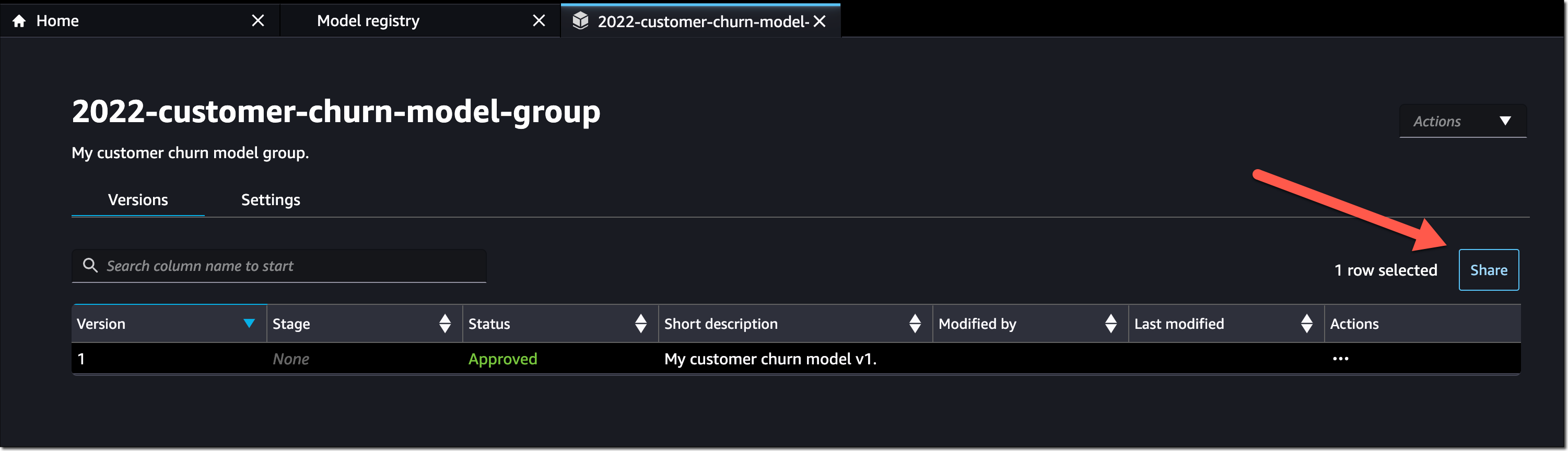
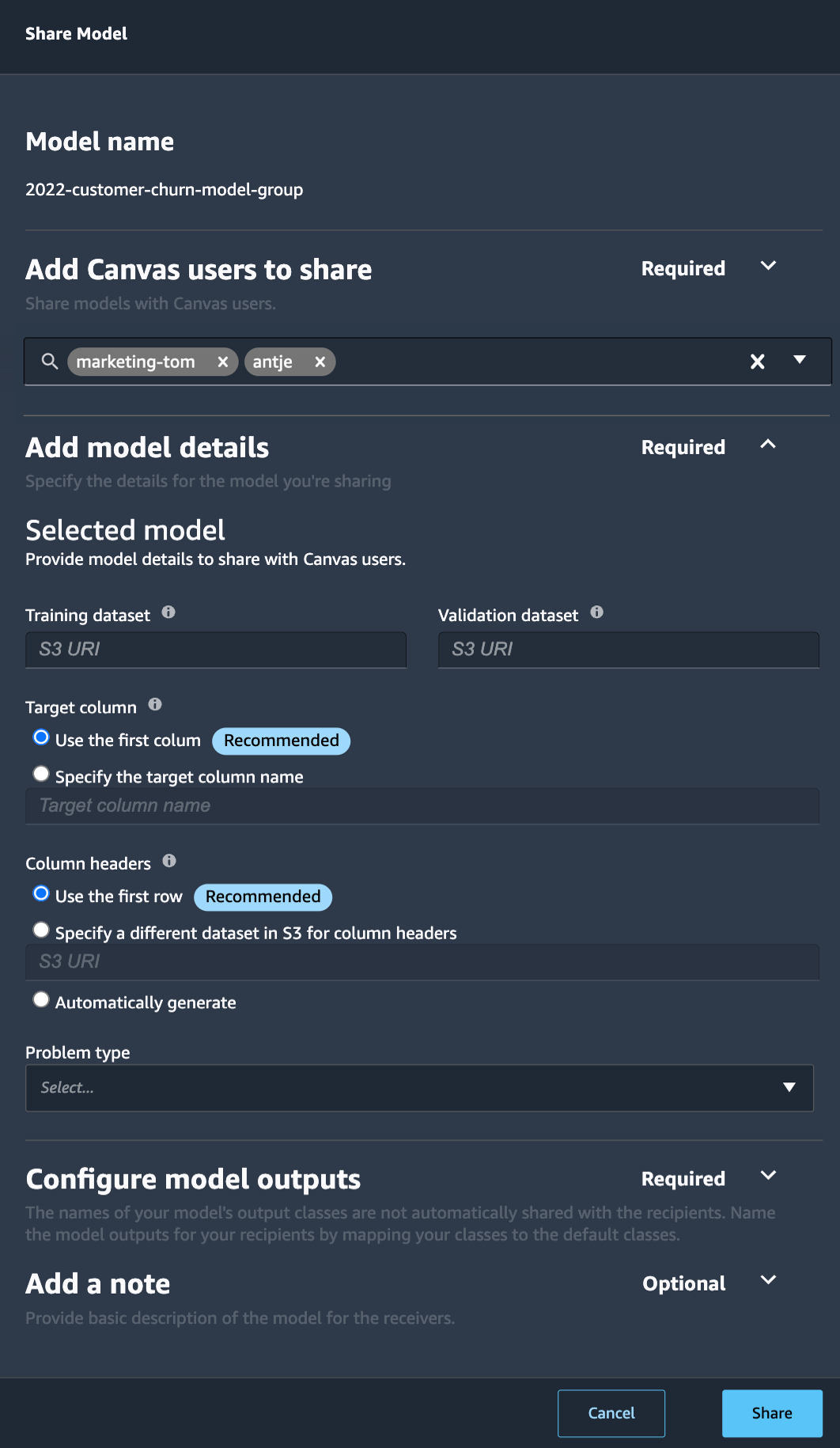
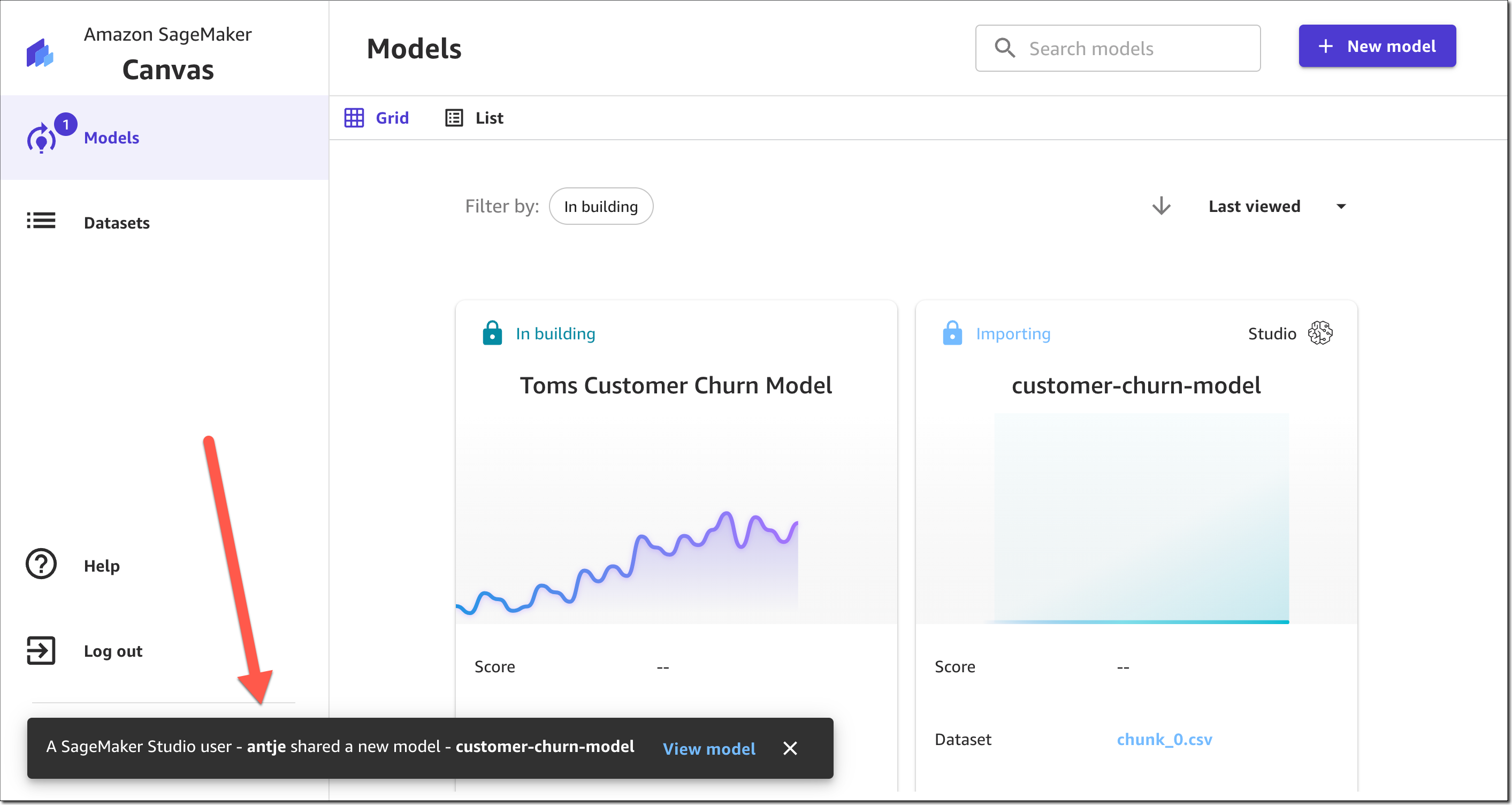
Amazon SageMaker turned 5 years old 
 . You can read the initial blog post we published at the time. To celebrate the event, the Amazon Science published this article where AWS’s Vice President Bratin Saha reflects on the past and future of AWS’s machine learning tools and AI services.
. You can read the initial blog post we published at the time. To celebrate the event, the Amazon Science published this article where AWS’s Vice President Bratin Saha reflects on the past and future of AWS’s machine learning tools and AI services.
The security blog published a great post about the Cedar policy language. It explains how Amazon Verified Permissions provides a pre-built, flexible permissions system that you can use to build permissions based on both ABAC and RBAC in your applications. Cedar policy language is also at the heart of Amazon Verified Access I blogged about during re:Invent.
And just like every week, my most excellent colleague Ricardo published the open source newsletter.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
AWS re:Invent recaps in your area. During the re:Invent week, we had lots of new announcements, and in the next weeks, you can find in your area a recap of all these launches. All the events will be posted on this site, so check it regularly to find an event nearby.
AWS re:Invent keynotes, leadership sessions, and breakout sessions are available on demand. I recommend that you check the playlists and find the talks about your favorite topics in one collection.
AWS Summits season will restart in Q2 2023. The dates and locations will be announced here.
Stay Informed
That is my selection for this week! Heads up – the Week in Review will be taking a short break for the end of the year, but we’ll be back with regular updates starting on January 9, 2023. To better keep up with all of this news, do not forget to check out the following resources:
- What’s New with AWS – All AWS announcements. Add the RSS feed to your news reader.
- The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in your local languages. Check the ones in French, German, Italian, and Spanish.
- AWS News Blog – This blog.
— seb
This post is part of our Week in Review series. Check back each week for a quick roundup of interesting news and announcements from AWS!