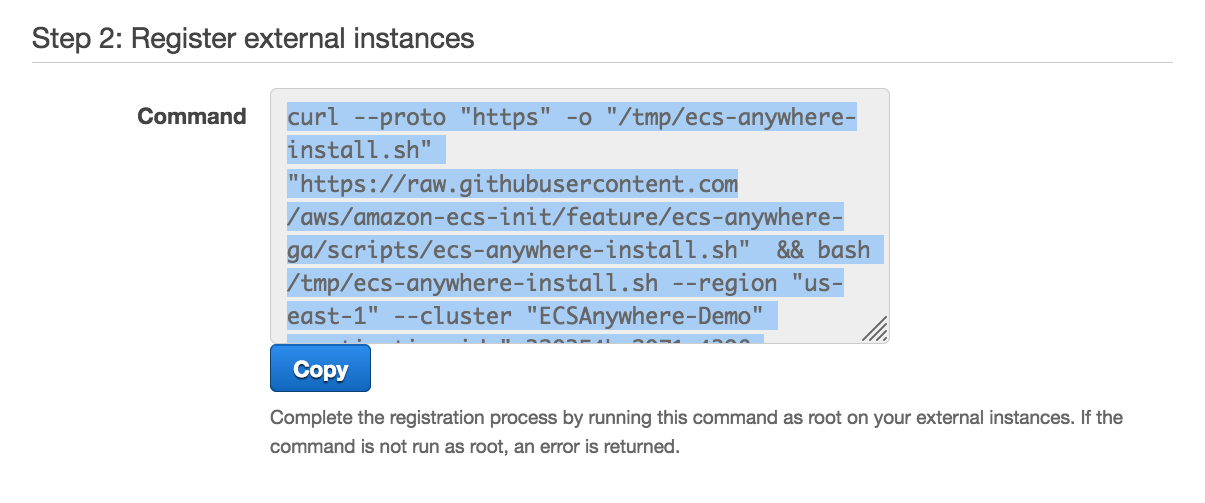
At AWS re:Invent 2022, we introduced in preview Amazon VPC Lattice, a new capability of Amazon Virtual Private Cloud (Amazon VPC) that gives you a consistent way to connect, secure, and monitor communication between your services. With VPC Lattice, you can define policies for network access, traffic management, and monitoring to connect compute services across instances, containers, and serverless applications.
Today, I am happy to share that VPC Lattice is now generally available. Compared to the preview, you have access to new capabilities:
- Services can use a custom domain name in addition to the domain name automatically generated by VPC Lattice. When using HTTPS, you can configure an SSL/TLS certificate that matches the custom domain name.
- You can deploy the open-source AWS Gateway API Controller to use VPC Lattice with a Kubernetes-native experience. It uses the Kubernetes Gateway API to let you connect services across multiple Kubernetes clusters and services running on EC2 instances, containers, and serverless functions.
- You can use an Application Load Balancer (ALB) or a Network Load Balancer (NLB) as a target for a service.
- The IP address target type now supports IPv6 connectivity.
Let’s see some of these new features in practice.
Using Amazon VPC Lattice for Service-to-Service Connectivity
In my previous post introducing VPC Lattice, I show how to create a service network, associate multiple VPCs and services, and configure target groups for EC2 instances and Lambda functions. There, I also show how to route traffic based on request characteristics and how to use weighted routing. Weighted routing is really handy for blue/green and canary-style deployments or for migrating from one compute platform to another.
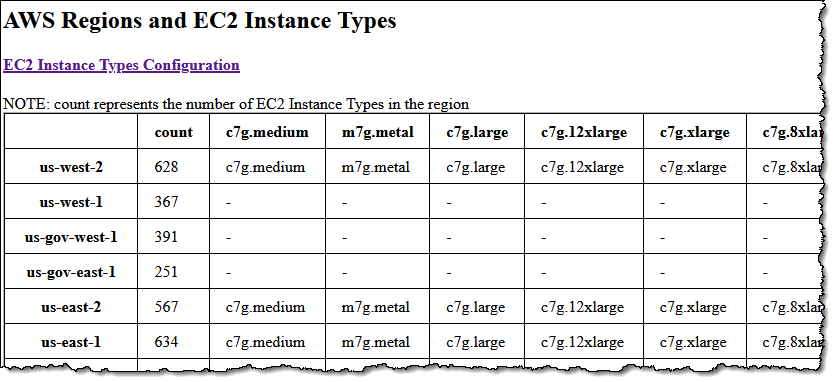
Now, let’s see how to use VPC Lattice to allow the services of an e-commerce application to communicate with each other. For simplicity, I only consider four services:
- The
Orderservice, running as a Lambda function. - The
Inventoryservice, deployed as an Amazon Elastic Container Service (Amazon ECS) service in a dual-stack VPC supporting IPv6. - The
Deliveryservice, deployed as an ECS service using an ALB to distribute traffic to the service tasks. - The
Paymentservice, running on an EC2 instance.
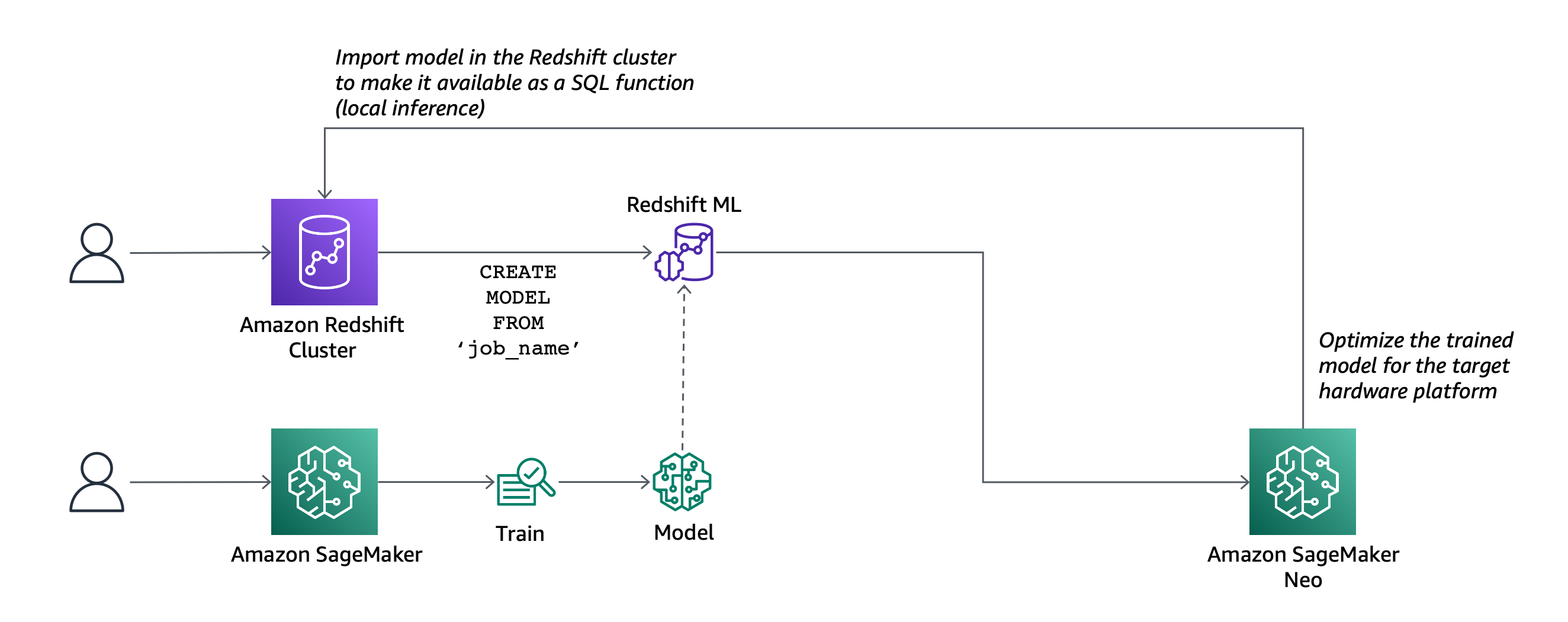
First, I create a service network. The Order service needs to call the Inventory service (to check if an item is available for purchase), the Delivery service (to organize the delivery of the item), and the Payment service (to transfer the funds). The following diagram shows the service-to-service communication from the perspective of the service network.

These services run in different AWS accounts and multiple VPCs. VPC Lattice handles the complexity of setting up connectivity across VPC boundaries and permission across accounts so that service-to-service communication is as simple as an HTTP/HTTPS call.
The following diagram shows how the communication flows from an implementation point of view.

The Order service runs in a Lambda function connected to a VPC. Because all the VPCs in the diagram are associated with the service network, the Order service is able to call the other services (Inventory, Delivery, and Payment) even if they are deployed in different AWS accounts and in VPCs with overlapping IP addresses.
Using a Network Load Balancer (NLB) as Target
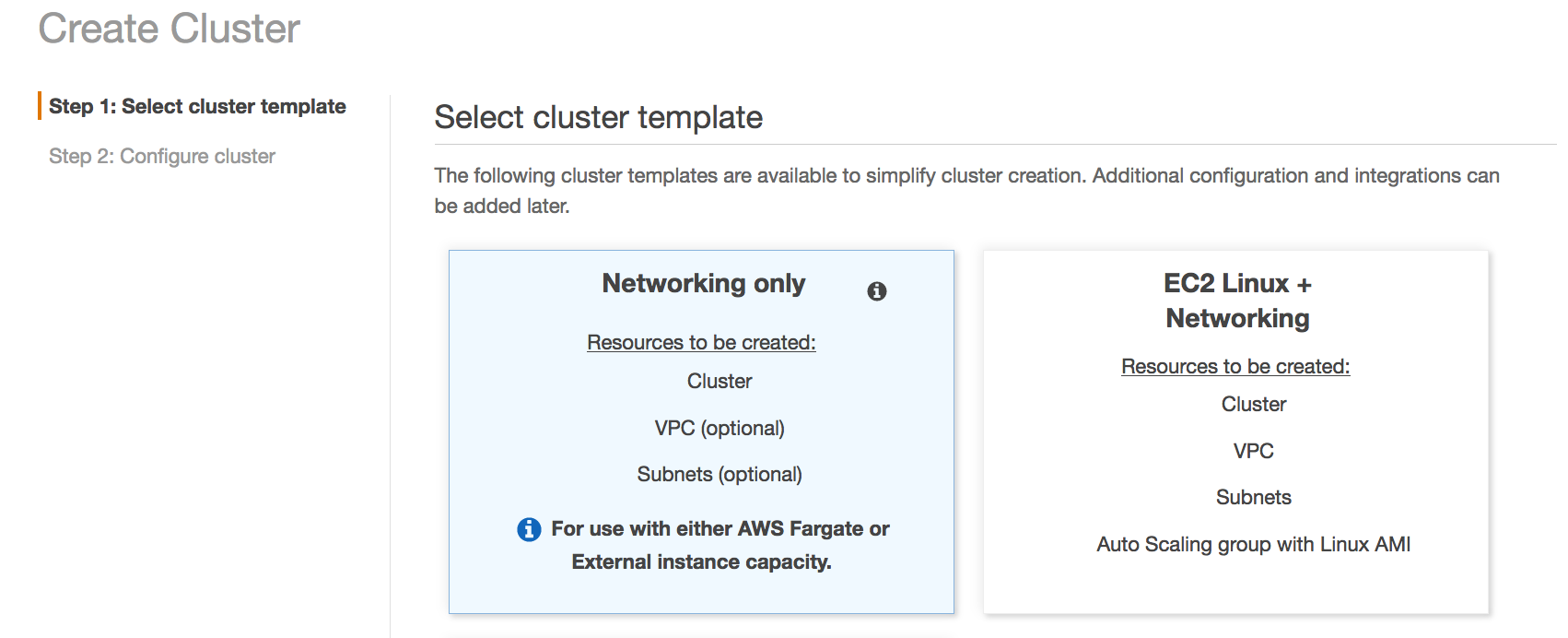
The Inventory service runs in a dual-stack VPC. It’s deployed as an ECS service with an NLB to distribute traffic to the tasks in the service. To get the IPv6 addresses of the NLB, I look for the network interfaces used by the NLB in the EC2 console.

When creating the target group for the Inventory service, under Basic configuration, I choose IP addresses as the target type. Then, I select IPv6 for the IP Address type.

In the next step, I enter the IPv6 addresses of the NLB as targets. After the target group is created, the health checks test the targets to see if they are responding as expected.

Using an Application Load Balancer (ALB) as Target
Using an ALB as a target is even easier. When creating a target group for the Delivery service, under Basic configuration, I choose the new Application Load Balancer target type.

I select the VPC in which to look for the ALB and choose the Protocol version.

In the next step, I choose Register now and select the ALB from the dropdown. I use the default port used by the target group. VPC Lattice does not provide additional health checks for ALBs. However, load balancers already have their own health checks configured.

Using Custom Domain Names for Services
To call these services, I use custom domain names. For example, when I create the Payment service in the VPC console, I choose to Specify a custom domain configuration, enter a Custom domain name, and select an SSL/TLS certificate for the HTTPS listener. The Custom SSL/TLS certificate dropdown shows available certificates from AWS Certificate Manager (ACM).

Securing Service-to-Service Communications
Now that the target groups have been created, let’s see how I can secure the way services communicate with each other. To implement zero-trust authentication and authorization, I use AWS Identity and Access Management (IAM). When creating a service, I select the AWS IAM as Auth type.

I select the Allow only authenticated access policy template so that requests to services need to be signed using Signature Version 4, the same signing protocol used by AWS APIs. In this way, requests between services are authenticated by their IAM credentials, and I don’t have to manage secrets to secure their communications.

Optionally, I can be more precise and use an auth policy that only gives access to some services or specific URL paths of a service. For example, I can apply the following auth policy to the Order service to give to the Lambda function these permissions:
- Read-only access (GET method) to the
Inventoryservice/stockURL path. - Full access (any HTTP method) to the
Deliveryservice/deliveryURL path.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<Order Service Lambda Function IAM Role ARN>"
},
"Action": "vpc-lattice-svcs:Invoke",
"Resource": "<Inventory Service ARN>/stock",
"Condition": {
"StringEquals": {
"vpc-lattice-svcs:RequestMethod": "GET"
}
}
},
{
"Effect": "Allow",
"Principal": {
"AWS": "<Order Service Lambda Function IAM Role ARN>"
},
"Action": "vpc-lattice-svcs:Invoke",
"Resource": "<Delivery Service ARN>/delivery"
}
]
}Using VPC Lattice, I quickly configured the communication between the services of my e-commerce application, including security and monitoring. Now, I can focus on the business logic instead of managing how services communicate with each other.
Availability and Pricing
Amazon VPC Lattice is available today in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), and Europe (Ireland).
With VPC Lattice, you pay for the time a service is provisioned, the amount of data transferred through each service, and the number of requests. There is no charge for the first 300,000 requests every hour, and you only pay for requests above this threshold. For more information, see VPC Lattice pricing.
We designed VPC Lattice to allow incremental opt-in over time. Each team in your organization can choose if and when to use VPC Lattice. Other applications can connect to VPC Lattice services using standard protocols such as HTTP and HTTPS. By using VPC Lattice, you can focus on your application logic and improve productivity and deployment flexibility with consistent support for instances, containers, and serverless computing.
Simplify the way you connect, secure, and monitor your services with VPC Lattice.
— Danilo