

The “managed” IoT Edge solution on Azure Stack Edge will be retired on 31 March 2024
Action recommended: Implement disaster recovery strategies for your Azure App Service web apps by 31 March 2025
We’ll no longer place apps in disaster recovery mode in the event of a regional disaster.
Action Required: Transition to DCR-based KQL transformations by 31 March 2026
Custom fields feature will be retired on 31 March 2026
Azure Database for PostgreSQL Single Server will be retired—migrate to Flexible Server by 28 March 2025
On 28 March 2025, Azure Database for PostgreSQL Single Server will be retired, and you’ll need to migrate to Azure Database for PostgreSQL Flexible Server by that date.
SQL Server connector’s V1 actions and triggers will be retired on 31 March 2024 – transition to SQL Server connector’s V2 actions and triggers
SQL Server connector’s V1 actions and triggers will be retired on 31 March 2024
Azure CDN will be retiring Azure CDN Standard from Akamai on 31 October 2023 – transition to another CDN profile to avoid service interruption
Azure CDN Standard from Akamai is being retired and services will end on 31 October 2023
Retirement notice: Migrate from Public Peering by March 31, 2024
ExpressRoute Public Peering will be retired on March 31, 2024.
Classic experience to protect VMware machines using Azure Site Recovery will be retired on 30 March 2026
Azure Site Recovery’s classic experience to protect VMware VMs will be retired on 30 March 2026
New – Ready-to-use Models and Support for Custom Text and Image Classification Models in Amazon SageMaker Canvas
Today AWS announces new features in Amazon SageMaker Canvas that help business analysts generate insights from thousands of documents, images, and lines of text in minutes with machine learning (ML). Starting today, you can access ready-to-use models and create custom text and image classification models alongside previously supported custom models for tabular data, all without requiring ML experience or writing a line of code.
Business analysts across different industries want to apply AI/ML solutions to generate insights from a variety of data and respond to ad-hoc analysis requests coming from business stakeholders. By applying AI/ML in their workflows, analysts can automate manual, time-consuming, and error-prone processes, such as inspection, classification, as well as extraction of insights from raw data, images, or documents. However, applying AI/ML to business problems requires technical expertise and building custom models can take several weeks or even months.
Launched in 2021, Amazon SageMaker Canvas is a visual, point-and-click service that allows business analysts to use a variety of ready-to-use models or create custom models to generate accurate ML predictions on their own.
Ready-to-use Models
Customers can use SageMaker Canvas to access ready-to-use models that can be used to extract information and generate predictions from thousands of documents, images, and lines of text in minutes. These ready-to-use models include sentiment analysis, language detection, entity extraction, personal information detection, object and text detection in images, expense analysis for invoices and receipts, identity document analysis, and more generalized document and form analysis.
For example, you can select the sentiment analysis ready-to-use model and upload product reviews from social media and customer support tickets to quickly understand how your customers feel about your products. Using the personal information detection ready-to-use model, you can detect and redact personally identifiable information (PII) from emails, support tickets, and documents. Using the expense analysis ready-to-use model, you can easily detect and extract data from your scanned invoices and receipts and generate insights about that data.
These ready-to-use models are powered by AWS AI services, including Amazon Rekognition, Amazon Comprehend, and Amazon Textract.

Custom Text and Image Classification Models
Customers that need custom models trained for their business-specific use-case can use SageMaker Canvas to create text and image classification models.
You can use SageMaker Canvas to create custom text classification models to classify data according to your needs. For example, imagine that you work as a business analyst at a company that provides customer support. When a customer support agent engages with a customer, they create a ticket, and they need to record the ticket type, for example, “incident”, “service request”, or “problem”. Many times, this field gets forgotten, and so, when the reporting is done, the data is hard to analyze. Now, using SageMaker Canvas, you can create a custom text classification model, train it with existing customer support ticket information and ticket type, and use it to predict the type of tickets in the future when working on a report with missing data.
You can also use SageMaker Canvas to create custom image classification models using your own image datasets. For instance, imagine you work as a business analyst at a company that manufactures smartphones. As part of your role, you need to prepare reports and respond to questions from business stakeholders related to quality assessment and it’s trends. Every time a phone is assembled, a picture is automatically taken, and at the end of the week, you receive all those images. Now with SageMaker Canvas, you can create a new custom image classification model that is trained to identify common manufacturing defects. Then, every week, you can use the model to analyze the images and predict the quality of the phones produced.
SageMaker Canvas in Action
Let’s imagine that you are a business analyst for an e-commerce company. You have been tasked with understanding the customer sentiment towards all the new products for this season. Your stakeholders require a report that aggregates the results by item category to decide what inventory they should purchase in the following months. For example, they want to know if the new furniture products have received positive sentiment. You have been provided with a spreadsheet containing reviews for the new products, as well as an outdated file that categorizes all the products on your e-commerce platform. However, this file does not yet include the new products.
To solve this problem, you can use SageMaker Canvas. First, you will need to use the sentiment analysis ready-to-use model to understand the sentiment for each review, classifying them as positive, negative, or neutral. Then, you will need to create a custom text classification model that predicts the categories for the new products based on the existing ones.
Ready-to-use Model – Sentiment Analysis
To quickly learn the sentiment of each review, you can do a bulk update of the product reviews and generate a file with all the sentiment predictions.
To get started, locate Sentiment analysis on the Ready-to-use models page, and under Batch prediction, select Import new dataset.
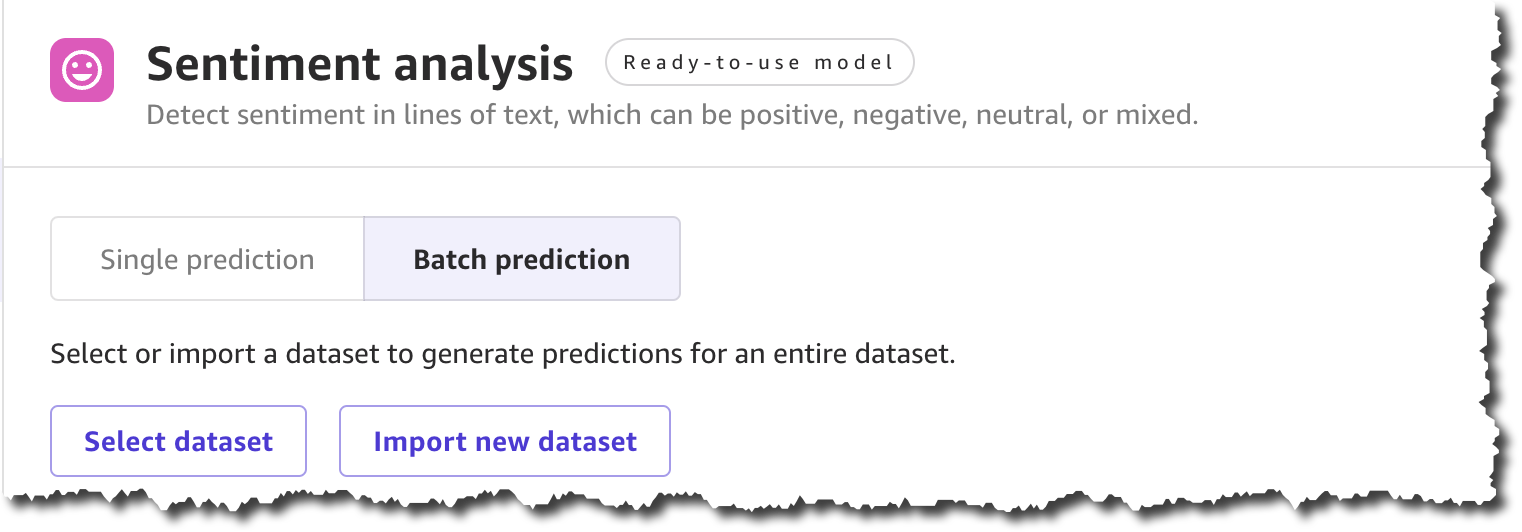
When you create a new dataset, you can upload the dataset from your local machine or use Amazon Simple Storage Service (Amazon S3). For this demo, you will upload the file locally. You can find all the product reviews used in this example in the Amazon Customer Reviews dataset.
After you complete uploading the file and creating the dataset, you can Generate predictions.
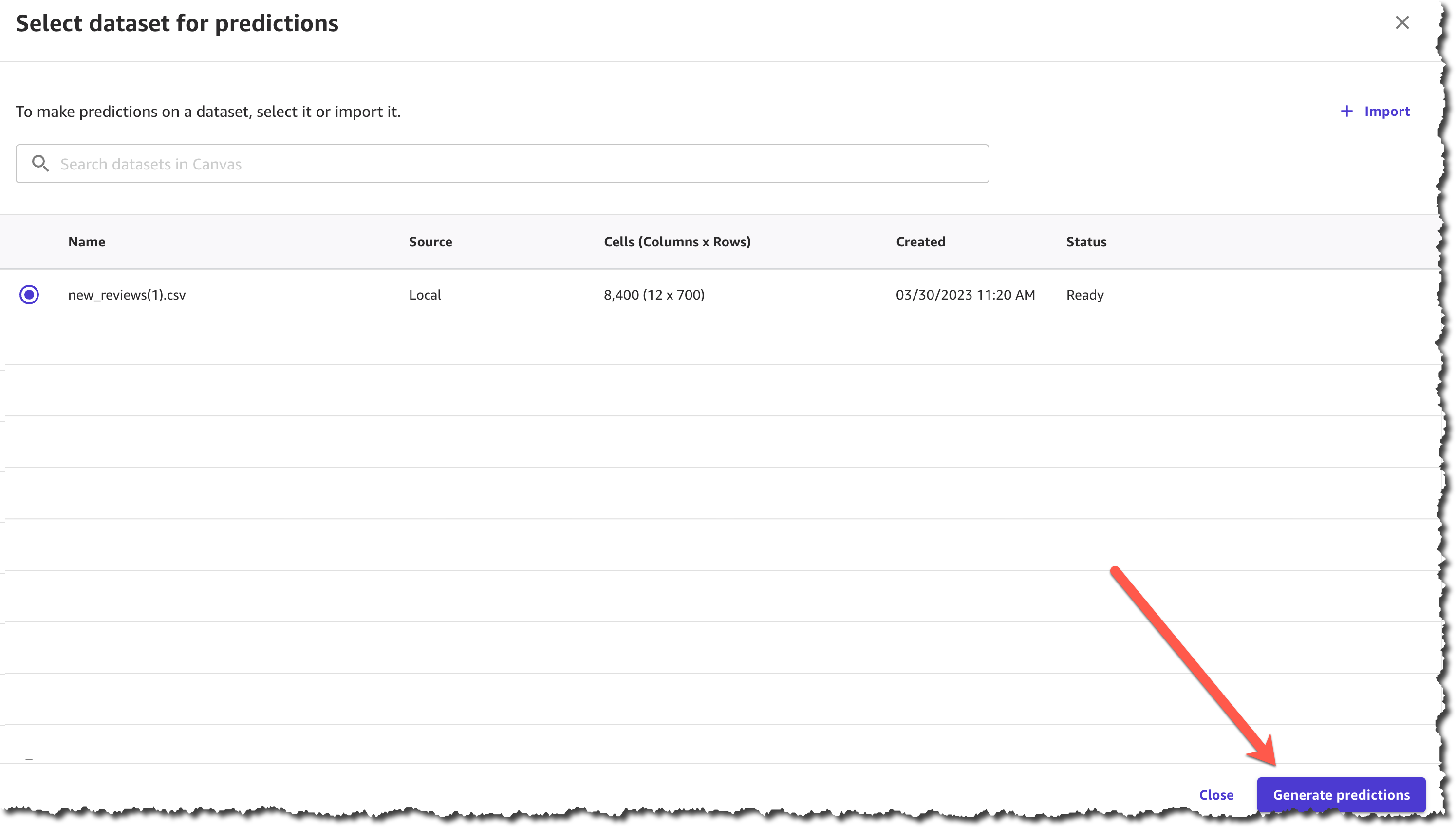
The prediction generation takes less than a minute, depending on the size of the dataset, and then you can view or download the results.

The results from this prediction can be downloaded as a .csv file or viewed from the SageMaker Canvas interface. You can see the sentiment for each of the product reviews.

Now you have the first part of your task ready—you have a .csv file with the sentiment of each review. The next step is to classify those products into categories.
Custom Text Classification Model
To classify the new products into categories based on the product title, you need to train a new text classification model in SageMaker Canvas.
In SageMaker Canvas, create a New model of the type Text analysis.

The first step when creating the model is to select a dataset with which to train the model. You will train this model with a dataset from last season, which contains all the products except for the new collection.
Once the dataset has finished importing, you will need to select the column that contains the data you want to predict, which in this case is the product_category column, and the column that will be used as the input for the model to make predictions, which is the product_title column.
After you finish configuring that, you can start to build the model. There are two modes of building:
- Quick build that returns a model in 15–30 minutes.
- Standard build takes 2–5 hours to complete.
To learn more about the differences between the modes of building you can check the documentation. For this demo, pick quick build, as our dataset is smaller than 50,000 rows.

When the model is built, you can analyze how the model performs. SageMaker Canvas uses the 80-20 approach; it trains the model with 80 percent of the data from the dataset and uses 20 percent of the data to validate the model.
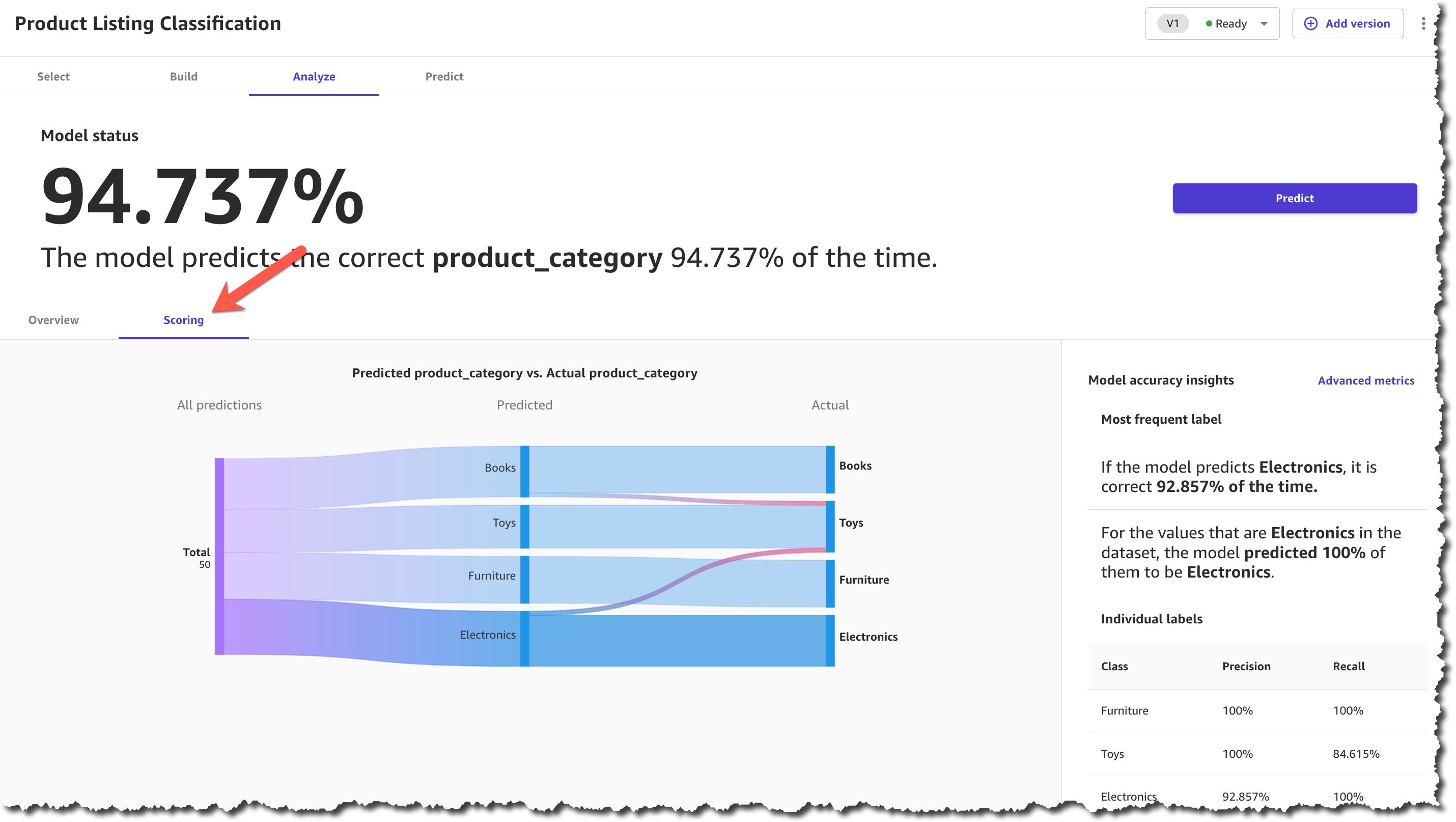
When the model finishes building, you can check the model score. The scoring section gives you a visual sense of how accurate the predictions were for each category. You can learn more about how to evaluate your model’s performance in the documentation.
After you make sure that your model has a high prediction rate, you can move on to generate predictions. This step is similar to the ready-to-use models for sentiment analysis. You can make a prediction on a single product or on a set of products. For a batch prediction, you need to select a dataset and let the model generate the predictions. For this example, you will select the same dataset that you selected in the ready-to-use model, the one with the reviews. This can take a few minutes, depending on the number of products in the dataset.
When the predictions are ready, you can download the results as a .csv file or view how each product was classified. In the prediction results, each product is assigned only one category based on the categories provided during the model-building process.

Now you have all the necessary resources to conduct an analysis and evaluate the performance of each product category with the new collection based on customer reviews. Using SageMaker Canvas, you were able to access a ready-to-use model and create a custom text classification model without having to write a single line of code.
Available Now
Ready-to-use models and support for custom text and image classification models in SageMaker Canvas are available in all AWS Regions where SageMaker Canvas is available. You can learn more about the new features and how they are priced by visiting the SageMaker Canvas product detail page.
— Marcia
Google Workspace Updates Weekly Recap – March 31, 2023
3 New updates
Unless otherwise indicated, the features below are fully launched or in the process of rolling out (rollouts should take no more than 15 business days to complete), launching to both Rapid and Scheduled Release at the same time (if not, each stage of rollout should take no more than 15 business days to complete), and available to all Google Workspace and G Suite customers.
Full mouse support now available for Google Sheets and Slides on Android
Last year, we announced full mouse support while using Google Docs on Android devices that mirrors mouse behavior on the web. This week, we’ve expanded this to Sheets and Slides, enabling you to resize unselected rows and columns, click, drag, hover, and more with your mouse. | Rolling out to Rapid Release domains now; launch to Scheduled Release domains planned for April 12, 2023.

Move folders from My Drive to shared drives
Earlier this year, we introduced a beta that allows end users to move folders from My Drive into shared drives. We’re happy to announce this is now generally available to Google Workspace Essentials, Business Standard, Business Plus, Enterprise Essentials, Enterprise Standard, Enterprise Plus, Education Fundamentals, Education Plus, Education Standard, the Teaching and Learning Upgrade, and Nonprofits, and legacy G Suite Business customers. | Rollout to Rapid Release domains complete; launch to Scheduled Release domains planned for April 11, 2023. | Learn more.
Multi-instance support now available for Google Keep on large screen Android devices
Following the recent update to view Google Keep notes on the home screen of Android devices, we’re introducing the ability to open a second instance of the Keep app on the same device. Having two windows open side-by-side enables better insight into your notes and gives you more ways to work with, display, and organize your content across Google Workspace.

Previous announcements
The announcements below were published on the Workspace Updates blog earlier this week. Please refer to the original blog posts for complete details.
Connected Sheets for Looker now available for all Looker-hosted instances
We’re making Connected Sheets available for Looker instances hosted on non-Google Cloud providers like AWS and Azure. | Available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Enterprise Standard, Enterprise Plus, Education Fundamentals, Education Plus, Education Standard, the Teaching and Learning Upgrade, Frontline, and Nonprofits only. | Learn more.
Launching in beta: manage working locations with the Calendar API
Available now in beta through our Developer Preview Program, you can read working location data using the Calendar API and get notified when those working locations change. |Available to Google Workspace Business Standard, Business Plus, Enterprise Standard, Enterprise Plus, Education Fundamentals, Education Plus, Education Standard, the Teaching and Learning Upgrade and Nonprofits customers, as well as legacy G Suite Business customers only. | Learn more.
Admins can install Chat apps for use in direct messages
Starting this week, admins can install Chat apps for direct messages on behalf of users within their domain from the Workspace Marketplace. | Available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Enterprise Standard, Enterprise Plus, Education Fundamentals, Education Plus, Education Standard, the Teaching and Learning Upgrade, Frontline, and legacy G Suite Basic and Business customers only. | Learn more.
Find files quicker with search chips in Google Drive
Last month, we pre-announced numerous features that offer new experiences in smart canvas, including enhancing Google Drive to help you complete your most frequent tasks more quickly. This week, we introduced search chips in Drive that enable you to filter by criteria like file type, owner, and last modified date. | Learn more.
Completed rollouts
The features below completed their rollouts to Rapid Release domains, Scheduled Release domains, or both. Please refer to the original blog post for additional details.
Rapid Release Domains:
Scheduled Release Domains:
Rapid and Scheduled Release Domains:
- Provide custom Google Meet background images for your users
- Improvements to content organization in Google Docs (Sidebar)
- Connected Sheets for Looker now available for all Looker-hosted instances
- Launching in beta: manage working locations with the Calendar API
- Quickly access Google Drive files in Chrome browser
For a recap of announcements in the past six months, check out What’s new in Google Workspace (recent releases).