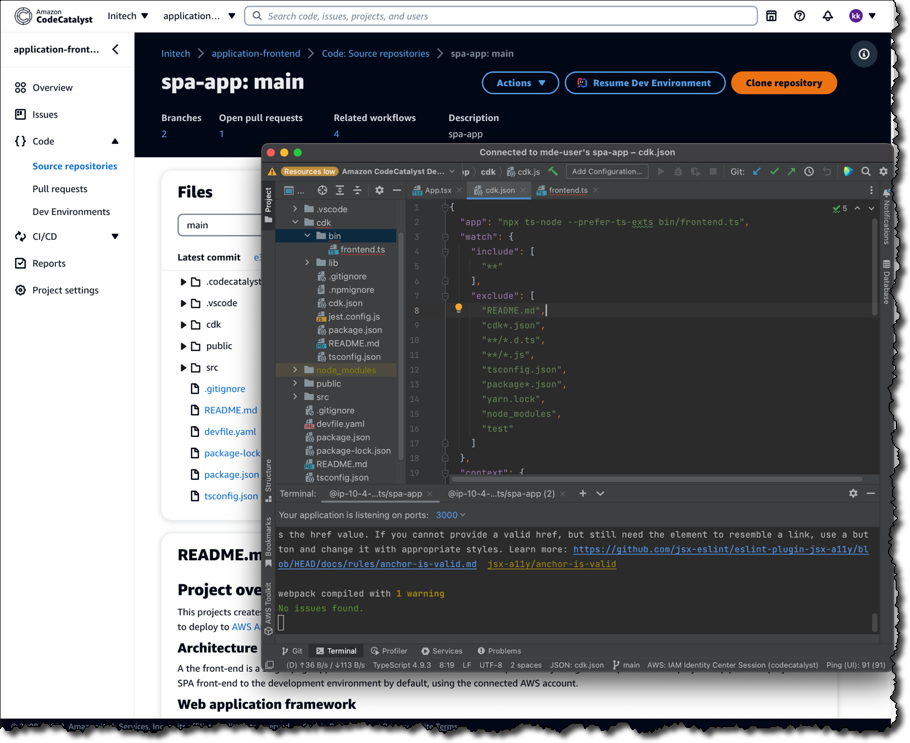
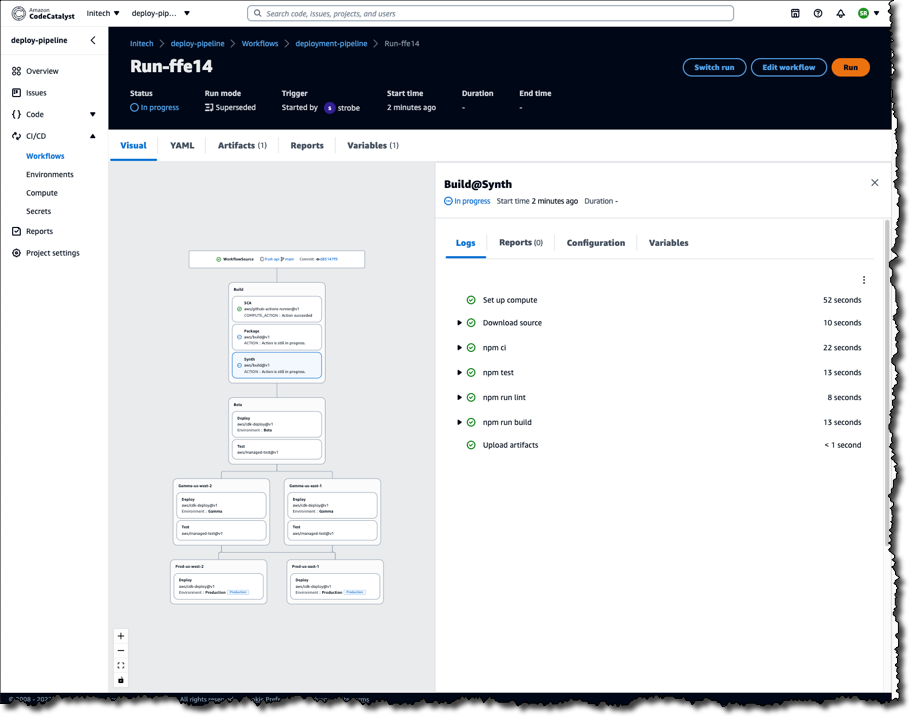
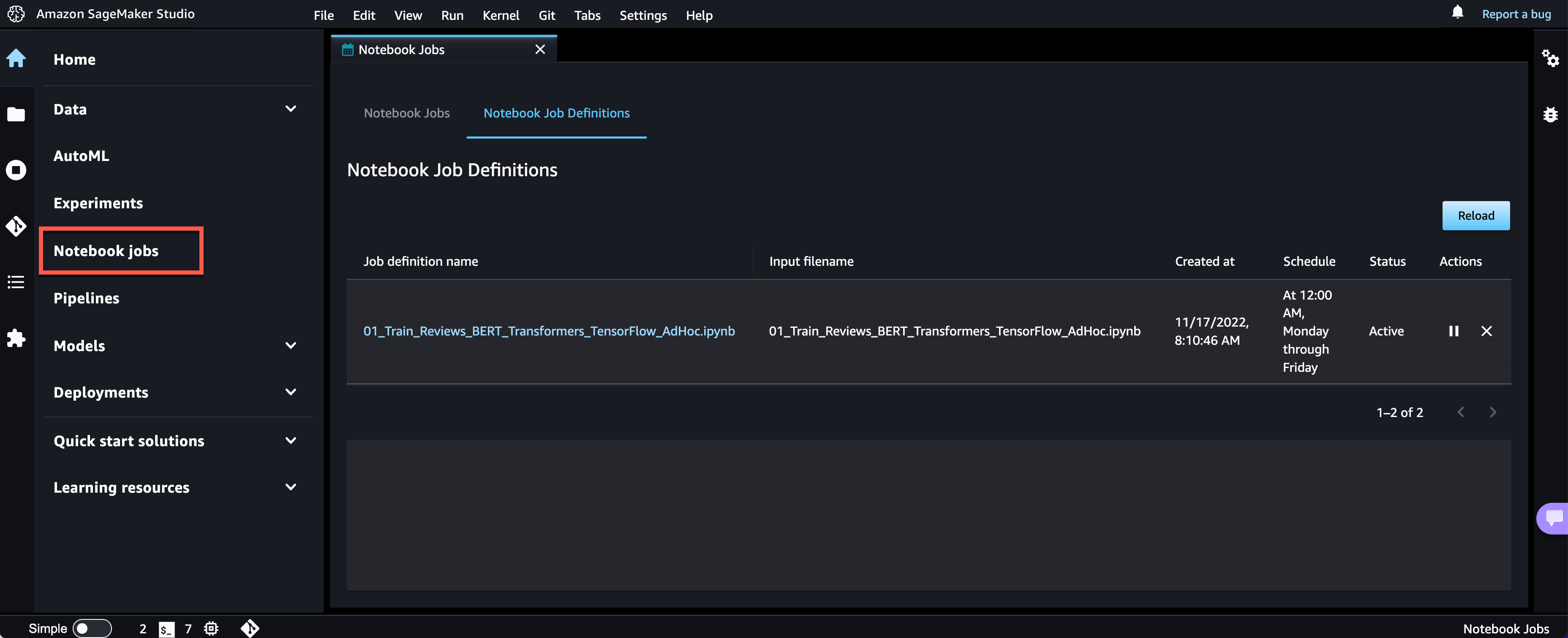
In 2016, we launched Amazon GameLift, a dedicated hosting solution that securely deploys and automatically scales fleets of session-based multiplayer game servers to meet worldwide player demand.
With Amazon GameLift, you can create and upload a game server build once, replicate, and then deploy across multiple AWS Regions and AWS Local Zones to reach your players with low-latency experiences across the world. GameLift also includes standalone features for low-cost game fleets with GameLift FleetIQ and player matchmaking with GameLift FlexMatch.
Game developers asked us to reduce the wait time to deploy a candidate server build to the cloud each time they needed to test and iterate their game during the development phase. In addition, our customers told us that they often have ongoing bare-metal contracts or on-premises game servers and want the flexibility to use their existing infrastructure with cloud servers.
Today we are announcing the general availability of Amazon GameLift Anywhere, which decouples game session management from the underlying compute resources. With this new release, you can now register and deploy any hardware, including your own local workstations, under a logical construct called an Anywhere Fleet.
Because your local hardware can now be a GameLift-managed server, you can iterate on the server build in your familiar local desktop environment, and any server error can materialize in seconds. You can also set breakpoints in your environment’s debugger, thereby eliminating trial and error and further speeding up the iteration process.
Here are the major benefits for game developers to use GameLift Anywhere.
- Faster game development – Instantly test and iterate on your local workstation while still leveraging GameLift FlexMatch and Queue services.
- Hybrid server management – Deploy, operate, and scale dedicated game servers hosted in the cloud or on-premises, all from a single location.
- Streamline server operations – Reduce cost and operational complexity by unifying server infrastructure under a single game server orchestration layer.
During the beta period of GameLift Anywhere, lots of customers gave feedback. For example, Nitro Games has been an Amazon GameLift customer since 2020 and have used the service for player matchmaking and managing dedicated game servers in the cloud. Daniel Liljeqvist, Senior DevOps Engineer at Nitro Games said “With GameLift Anywhere we can easily debug a game server on our local machine, saving us time and making the feedback loop much shorter when we are developing new games and features.”
GameLift Anywhere resources such as locations, fleets, and compute are managed through the same highly secure AWS API endpoints as all AWS services. This also applies to generating the authentication tokens for game server processes that are only valid for a limited amount of time for additional security. You can leverage AWS Identity and Access Management (AWS IAM) roles and policies to fully manage access to all the GameLift Anywhere endpoints.
Getting Started with GameLift Anywhere
Before creating your GameLift fleet in your local hardware, you can create custom locations to run your game builds or scripts. Choose Locations in the left navigation pane of the GameLift console and select Create location.
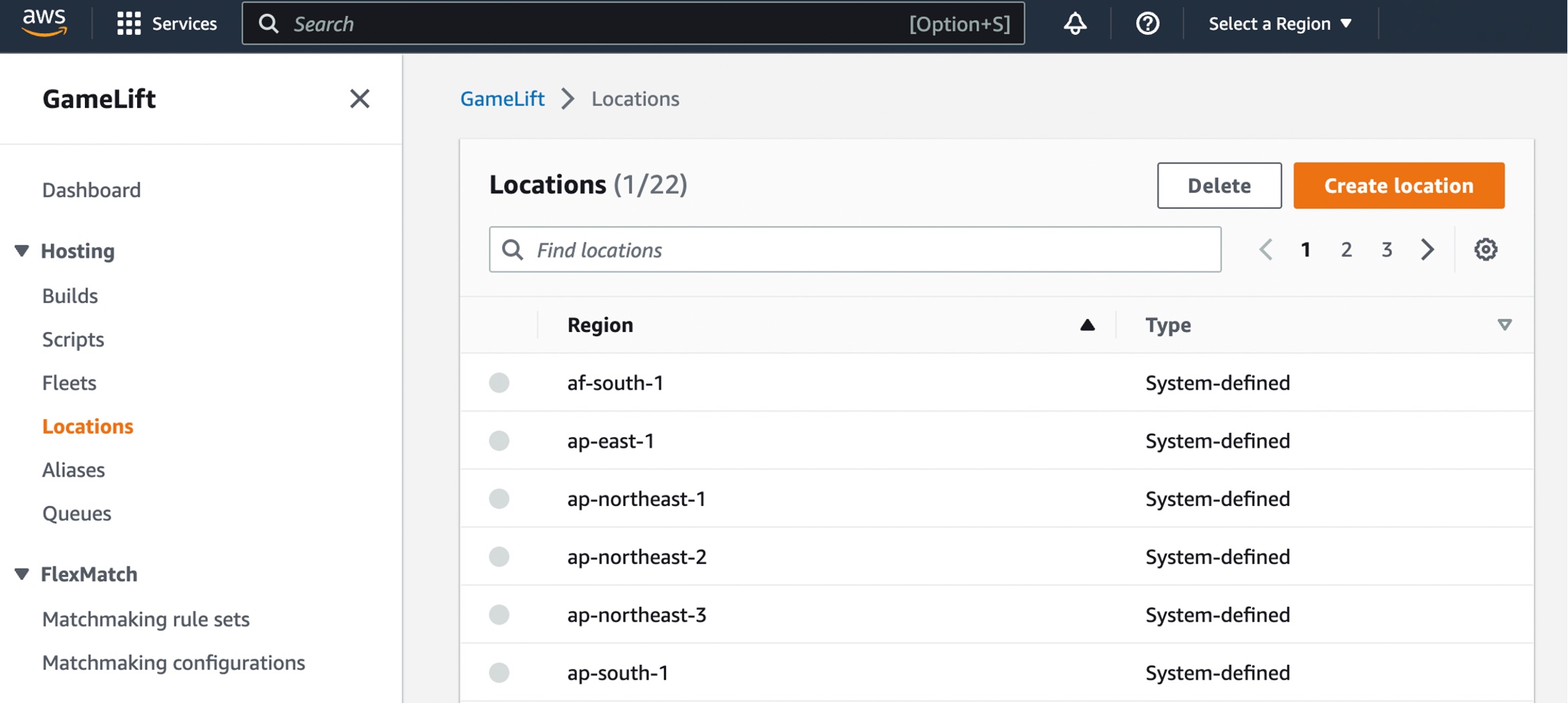
You can create a custom location of your hardware that you can use with your GameLift Anywhere fleet to test your games.
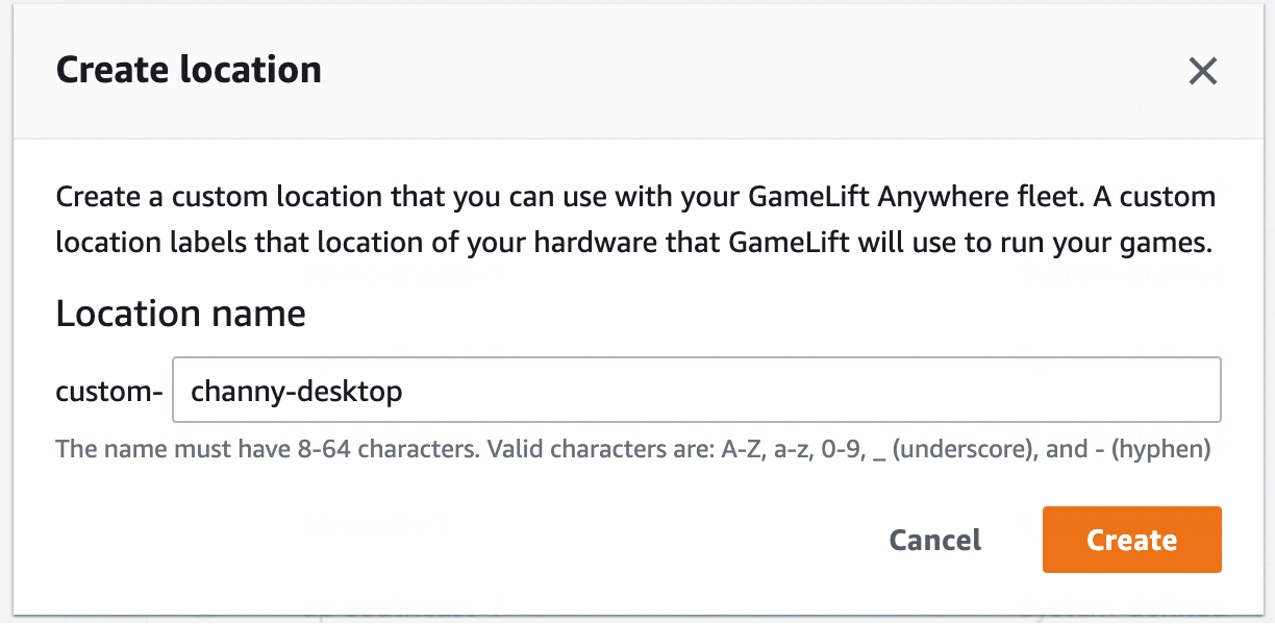
Choose Fleets from the left navigation pane, then choose Create fleet to add your GameLift Anywhere fleet in the desired location.
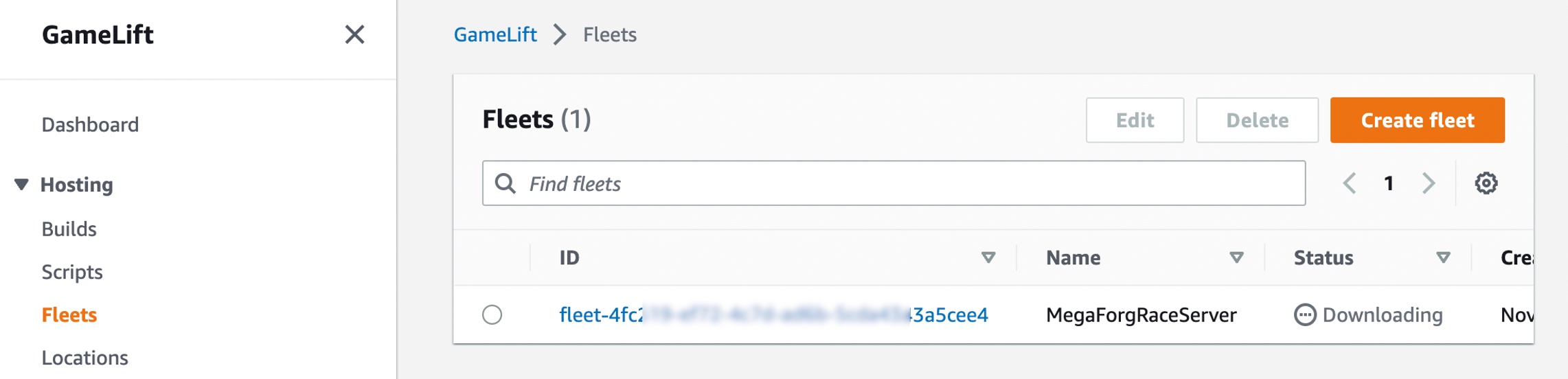
Choose Anywhere on the Choose compute type step.
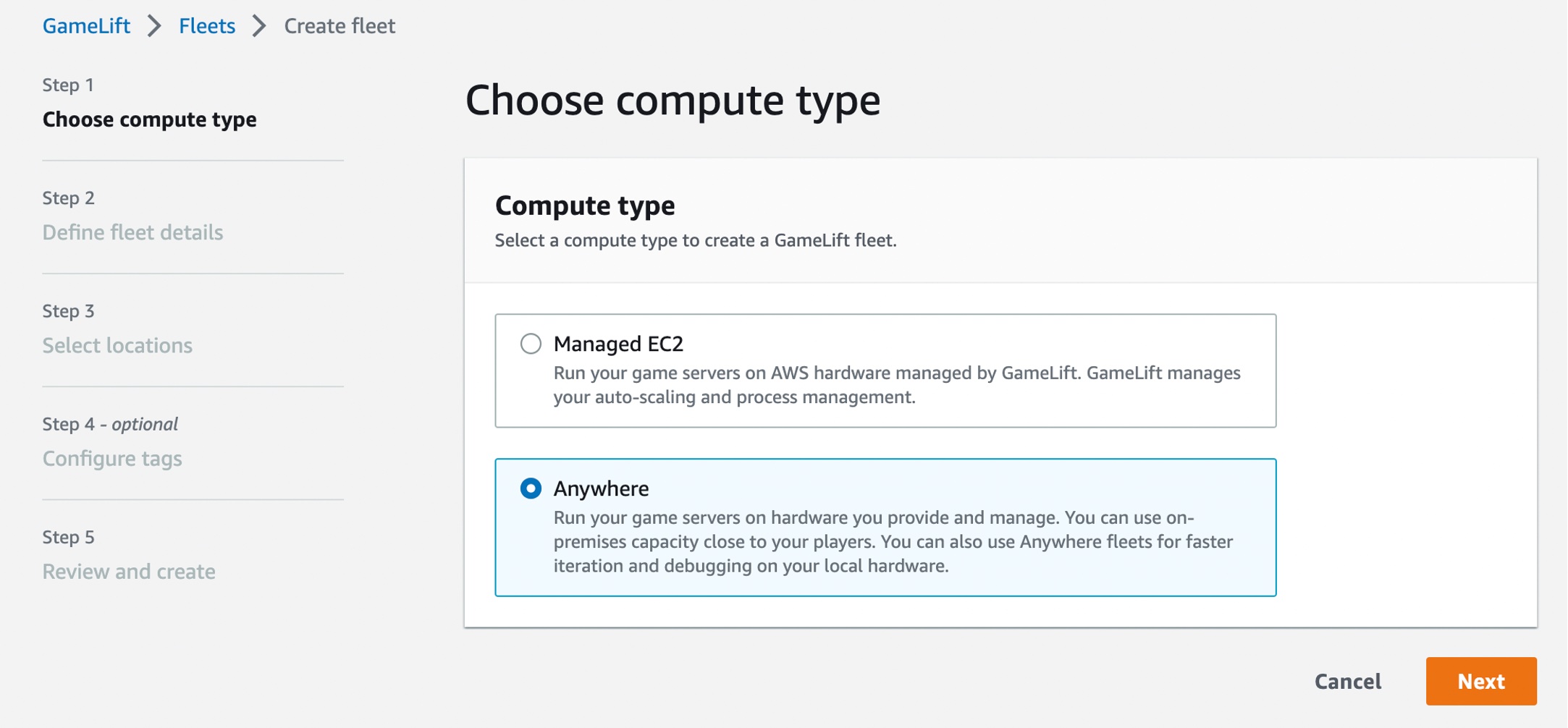
Define your fleet details, such as a fleet name and optional items. For more information on settings, see Create a new GameLift fleet in the AWS documentation.
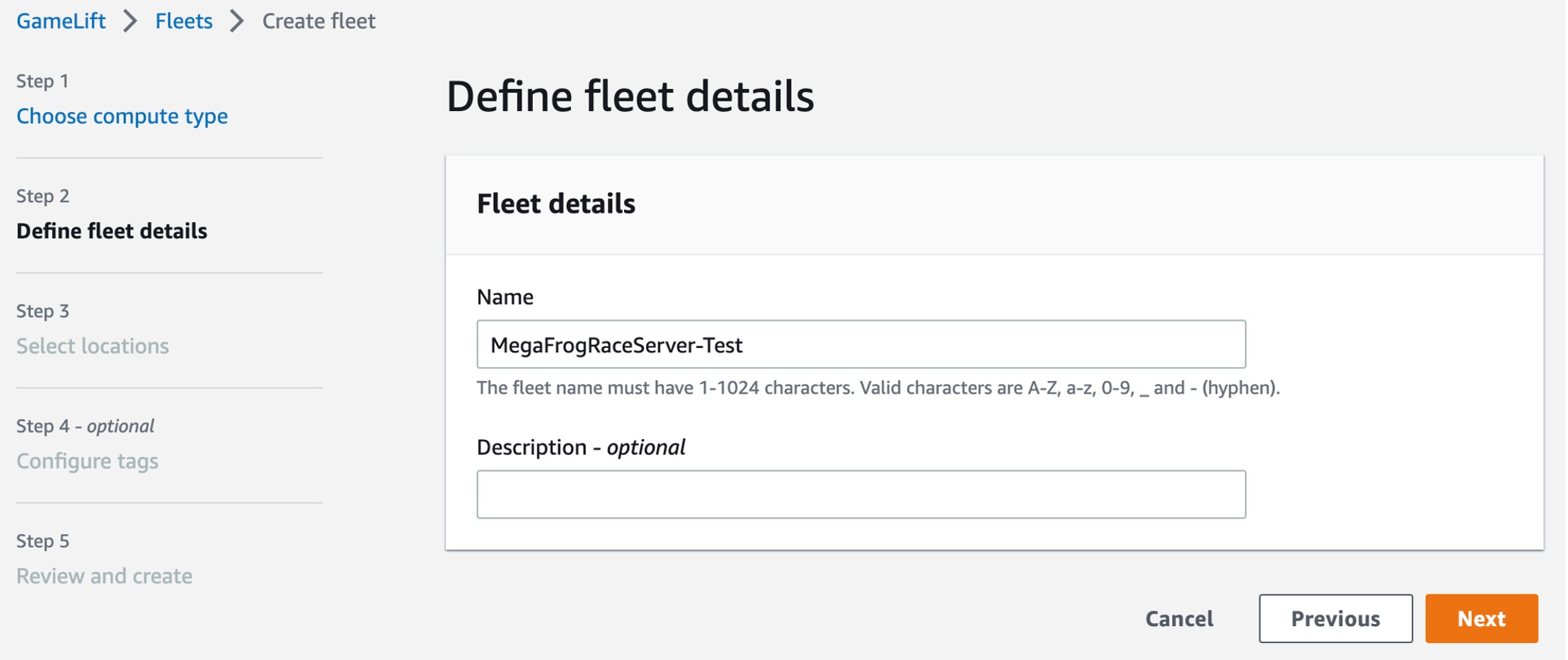
On the Select locations step, select the custom location that you created. The home AWS Region is automatically selected as the Region you are creating the fleet in. You can use the home Region to access and use your resources.
After completing the fleet creation steps to create your Anywhere fleet, you can see active fleets in both the managed EC2 instances and the Anywhere location. You also can integrate remote on-premises hardware by adding more GameLift Anywhere locations, so you can manage your game sessions from one place. To learn more, see Create a new GameLift fleet in the AWS documentation.
You can register your laptop as a compute resource in the fleet that you created. Use the fleet-id created in the previous step and add a compute-name and your laptop’s ip-address.
$ aws gamelift register-compute
--compute-name ChannyDevLaptop
--fleet-id fleet-12345678-abcdefghi
--ip-address 10.1.2.3Now, you can start a debug session of your game server by retrieving the authorization token for your laptop in the fleet that you created.
$ aws gamelift get-compute-auth-token
--fleet-id fleet-12345678-abcdefghi
--compute-name ChannyDevLaptopTo run a debug instance of your game server executable, your game server must call InitSDK(). After the process is ready to host a game session, the game server calls ProcessReady(). To learn more, see Integrating games with custom game servers and Testing your integration in the AWS documentation.
Now Available
Amazon GameLift Anywhere is available in all Regions where Amazon GameLift is available. GameLift offers a step-by-step developer guide, API reference guide, and GameLift SDKs. You can also see for yourself how easy it is to test Amazon GameLift using our sample game to get started.
Give it a try, and please send feedback to AWS re:Post for Amazon GameLift or through your usual AWS support contacts.
– Channy