Containers have become the default way that I package my web applications. Although I love the speed, productivity, and consistency that containers provide, there is one aspect of the container development workflow that I do not like: the lengthy routine I go through when I deploy a container image for the first time.
You might recognize this routine: setting up a load balancer, configuring the domain, setting up TLS, creating a CI/CD pipeline, and deploying to a container service.
Over the years, I have tweaked my workflow and I now have a boilerplate AWS Cloud Development Kit project that I use, but it has taken me a long time to get to this stage. Although this boilerplate project is great for larger applications, it does feel like a lot of work when all I want to do is deploy and scale a single container image.
At AWS, we have a number of services that provide granular control over your containerized application, but many customers have asked if AWS can handle the configuration and operations of their container environments. They simply want to point to their existing code or container repository and have their application run and scale in the cloud without having to configure and manage infrastructure services.
Because customers asked us to create something simpler, our engineers have been hard at work creating a new service you are going to love.
Introducing AWS App Runner
AWS App Runner makes it easier for you to deploy web apps and APIs to the cloud, regardless of the language they are written in, even for teams that lack prior experience deploying and managing containers or infrastructure. The service has AWS operational and security best practices built-it and automatically scale up or down at a moment’s notice, with no cold starts to worry about.
Deploying from Source
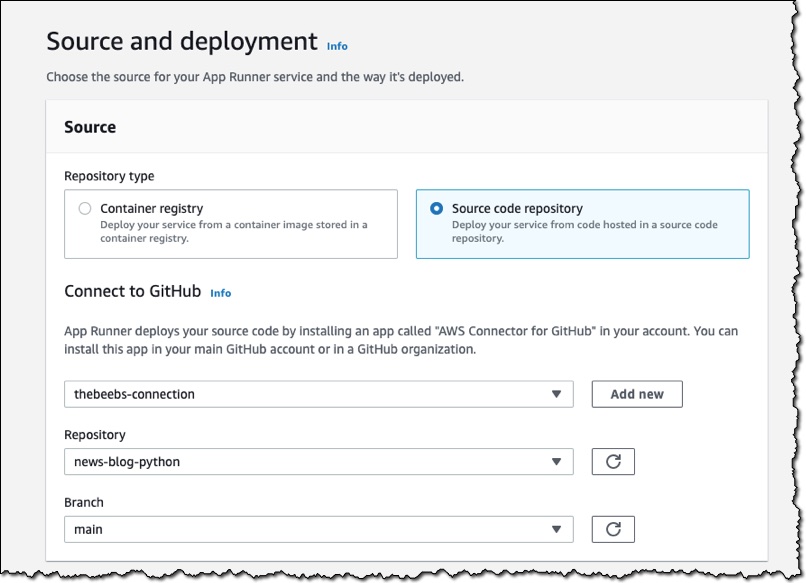
App Runner can deploy your app by either connecting to your source code or to a container registry. I will first show you how it works when connecting to source code. I have a Python web application in a GitHub repository. I will connect App Runner to this project, so you can see how it compiles and deploys my code to AWS.
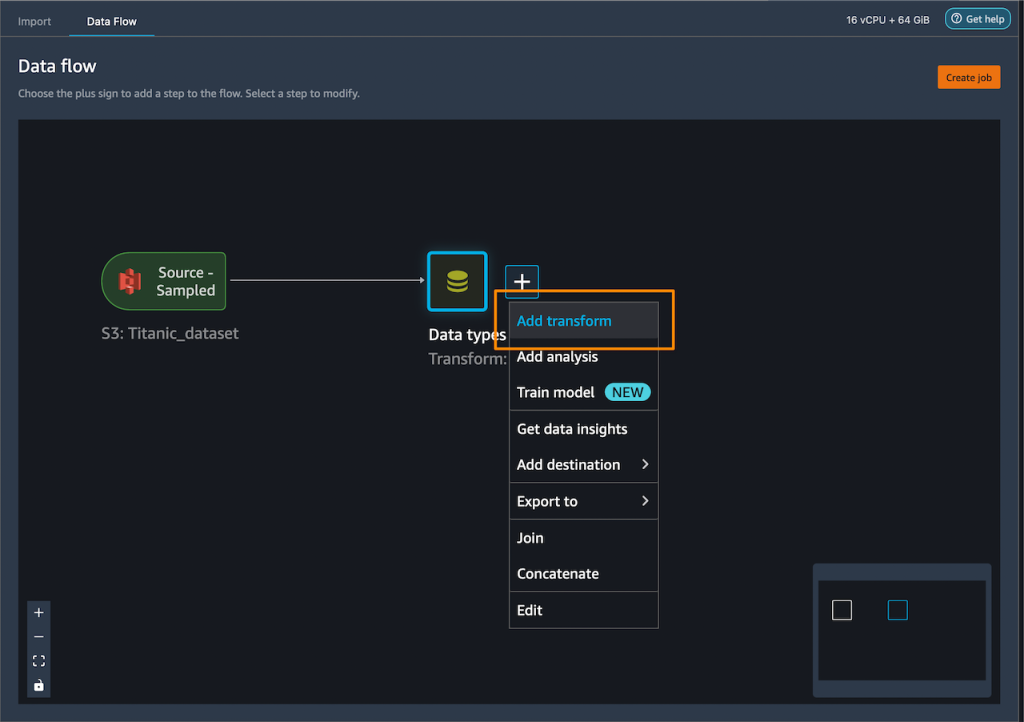
In the App Runner console, I choose Create an App Runner service.
For Repository type, I choose Source code repository and then follow the instructions to connect the service to my GitHub account. For Repository, I choose the repository that contains the application I want to deploy. For Branch, I choose main.
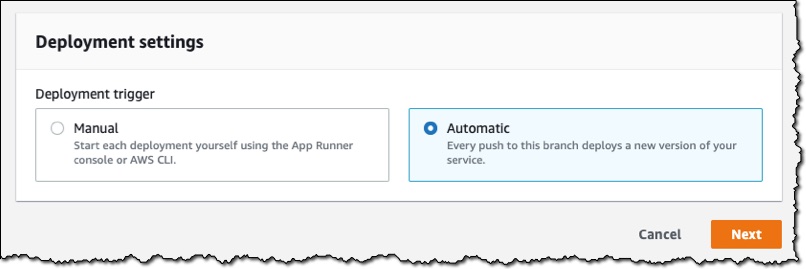
For Deployment trigger, I choose Automatic. This means when App Runner discovers a change to my source code, it automatically builds and deploys the updated version to my App Runner service
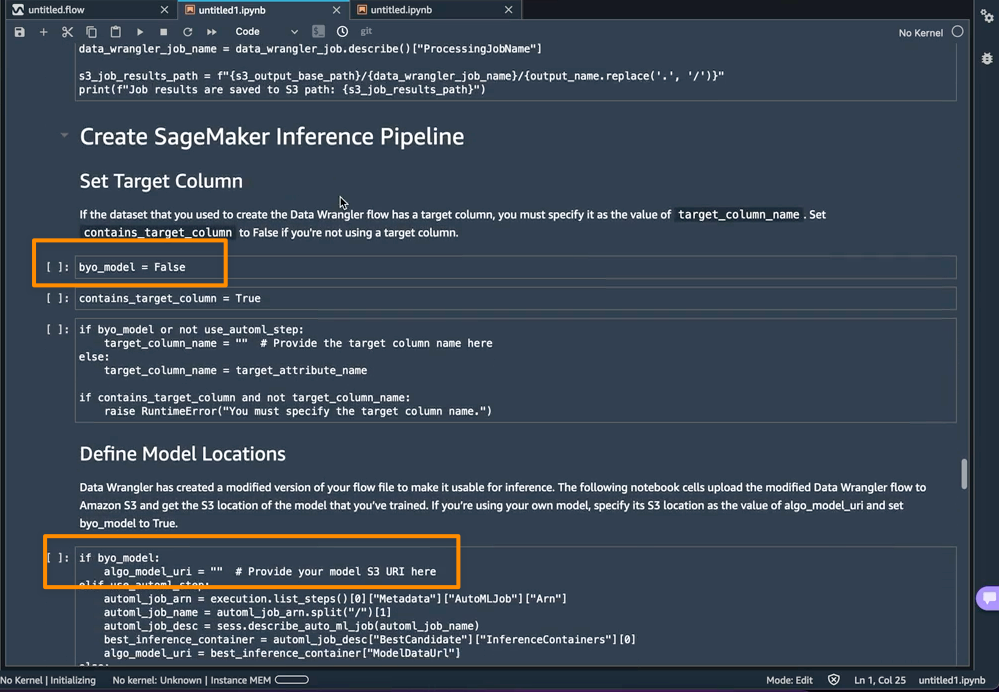
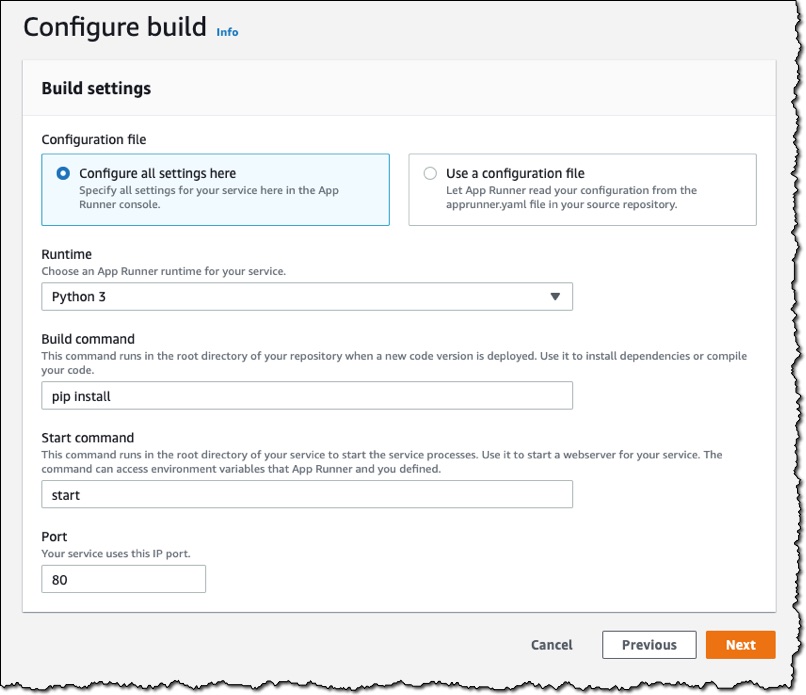
I can now configure the build. For Runtime, I choose Python 3. The service currently supports two languages: Python and Node.js. If you require other languages, then you will need to use the container registry workflow (which I will demonstrate later). I also complete the Build command, Start command, and Port fields, as shown here:
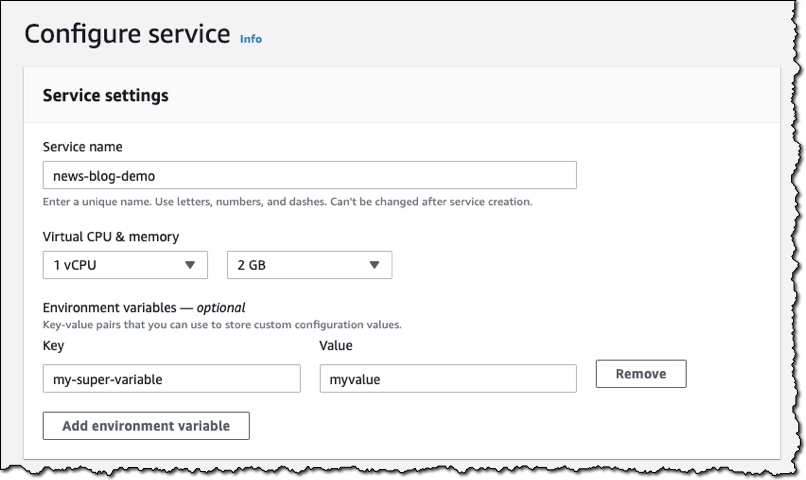
I now give my service a name and choose the CPU and memory size that I want my container to have. The choices I make here will affect the price I pay. Because my application requires very little CPU or memory, I choose 1 vCPU and 2 GB to keep my costs low. I can also provide any environment variables here to configure my application.
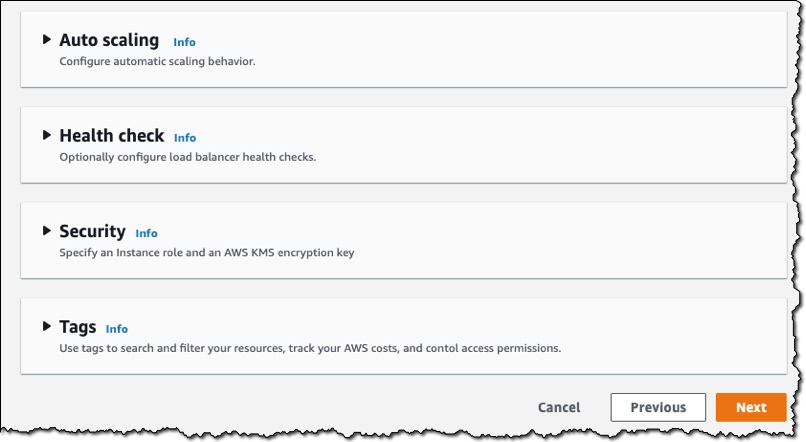
The console allows me to customize several different settings for my service.
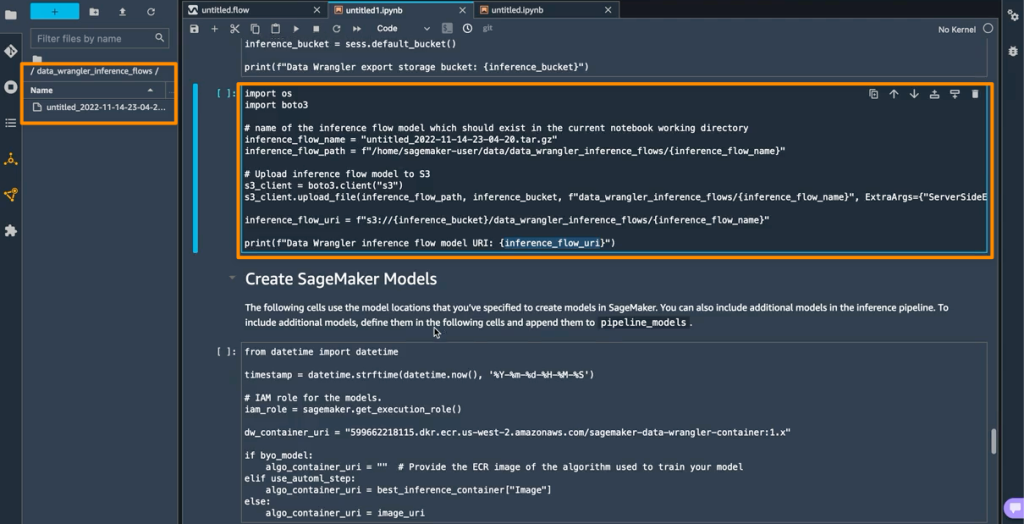
I can configure the auto scaling behavior. By default, my service will have one instance of my container image, but if the service receives more than 80 concurrent requests, it will scale to multiple instances. You can optionally specify a maximum number for cost control.
I can expand Health check, and set a path to which App Runner sends health check requests. If I do not set the path, App Runner attempts to make a TCP connection to verify health. By default, if App Runner receives five consecutive health check failures, it will consider the instance unhealthy and replace it.
I can expand Security, and choose an IAM role to be used by the instance. This will give permission for the container to communicate with other AWS services. App Runner encrypts all stored copies of my application source image or source bundle. If I provide a customer-managed key (CMK), App Runner uses it to encrypt my source. If I do not provide one, App Runner uses an AWS-managed key instead.
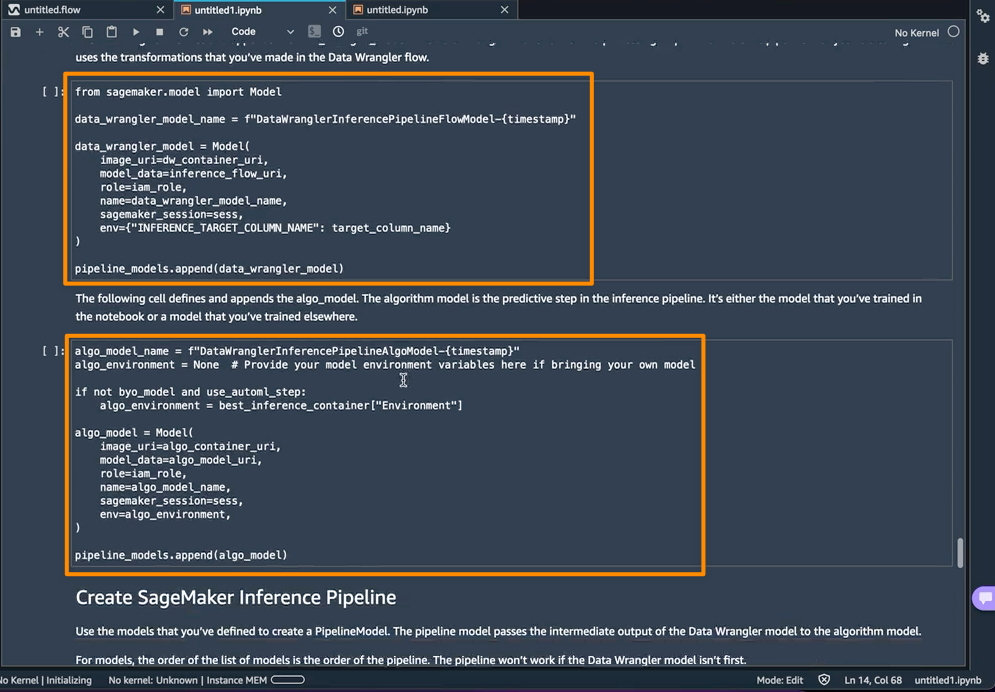
Finally, I review the configuration of the service and then choose Create & deploy.
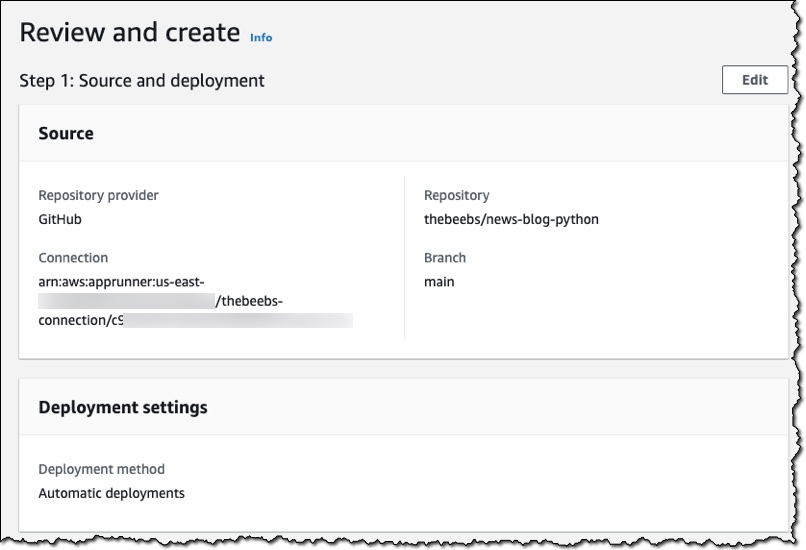
After a few minutes, my application was deployed and the service provided a URL that points to my deployed web application. App Runner ensures that https is configured so I can share it with someone on my team to test the application, without them receiving browser security warnings. I do not need to implement the handling of HTTPS secure traffic in my container image App Runner configures the whole thing.
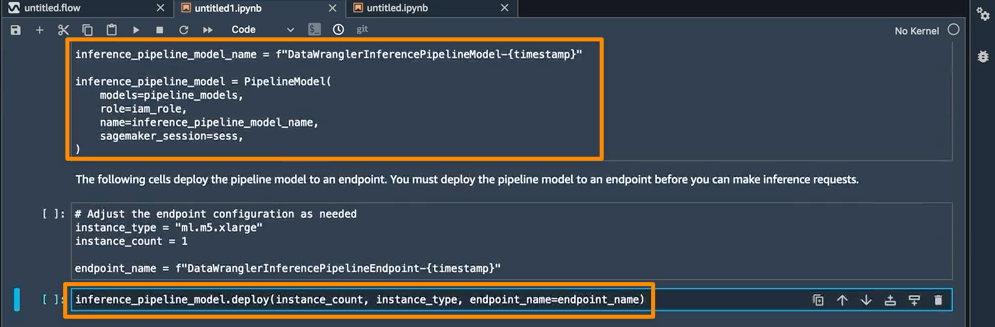
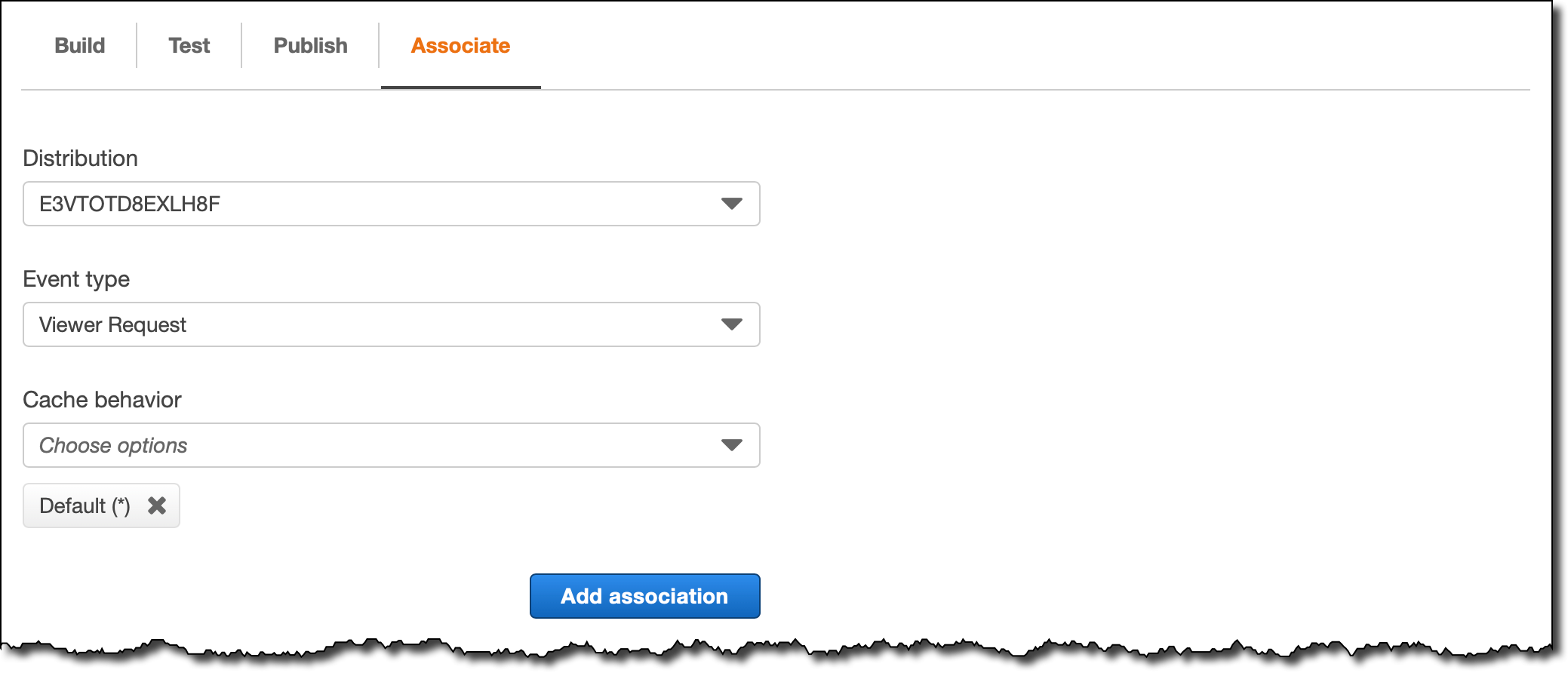
I now want to set up a custom domain. The service allows me to configure it without leaving the console. I open my service, choose the Custom domains tab, and then choose Add domain.
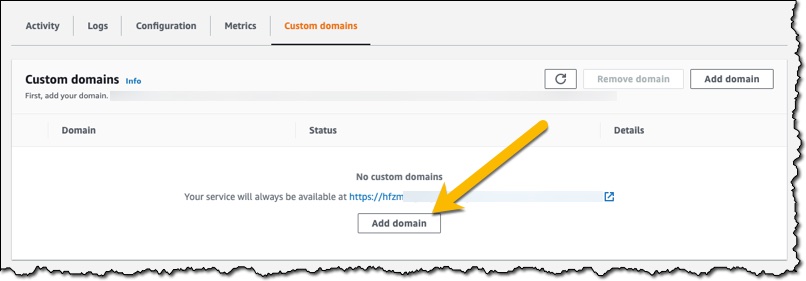
In Domain name, I enter the domain I want to use for my app, and then choose Save.
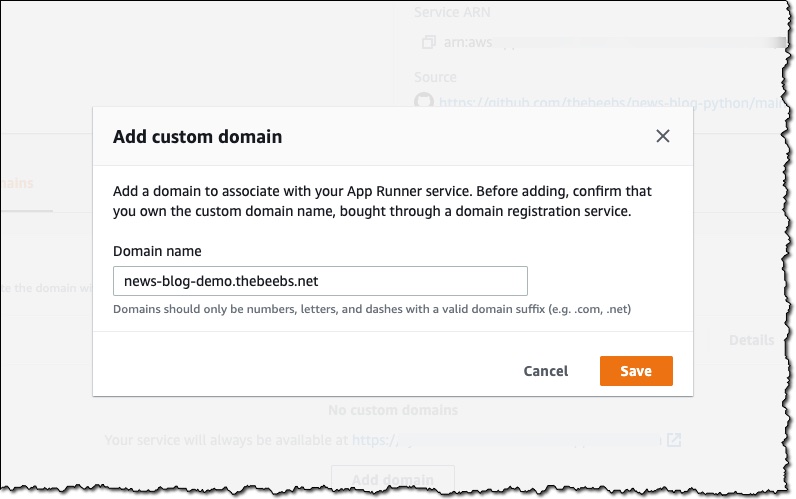
After I prove ownership of the domain, the app will be available at my custom URL. Next, I will show you how App Runner works with container images.
Deploy from a Container Image
I created a .NET web application, built it as a container image, and then pushed this container image to Amazon ECR Public (our public container registry).
Just as I did in the first demo, I choose Create service. On Source and deployment, for Repository type, I choose Container registry. For Provider, I choose Amazon ECR Public. In Container image URI, I enter the URI to the image.
The deployment settings now only provide the option to manually trigger the deployment. This is because I chose Amazon ECR Public. If I wanted to deploy every time a container changed, then for Provider, I would need to choose Amazon ECR.
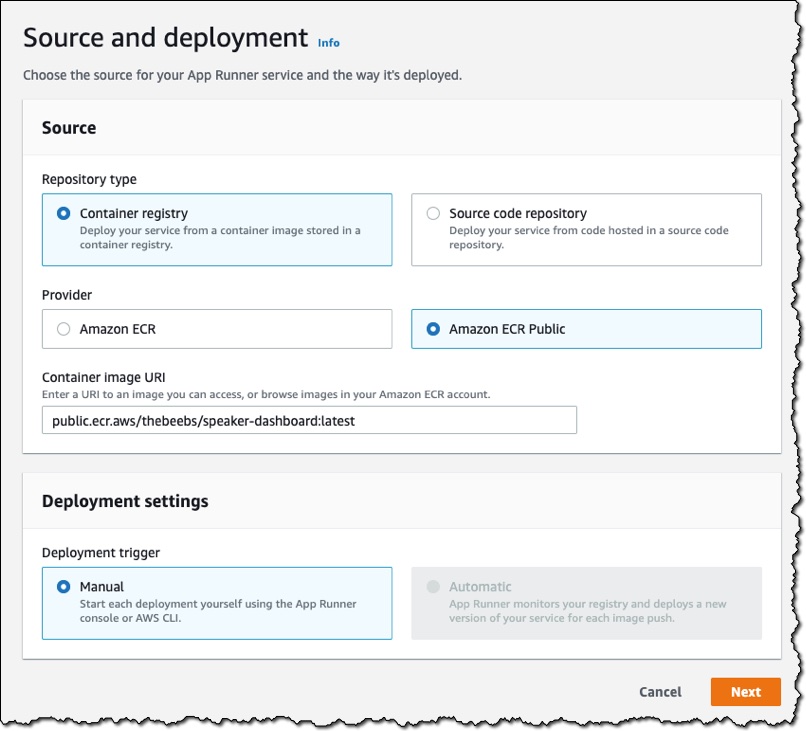
From this point on, the instructions are identical to those in the “Deploying from Source” section. After the deployment, the service provides a URL, and my application is live on the internet.
Things to Know
App Runner implements the file system in your container instance as ephemeral storage. Files are temporary. For example, they do not persist when you pause and resume your App Runner service. More generally, files are not guaranteed to persist beyond the processing of a single request, as part of the stateless nature of your application. Stored files do, however, take up part of the storage allocation of your App Runner service for the duration of their lifespan. Although ephemeral storage files are not guaranteed to persist across requests, they might sometimes persist. You can opportunistically take advantage of it. For example, when handling a request, you can cache files that your application downloads if future requests might need them. This might speed up future request handling, but I cannot guarantee the speed gains. Your code should not assume that a file that has been downloaded in a previous request still exists. For guaranteed caching, use a high-throughput, low-latency, in-memory data store like Amazon ElastiCache.
Partners in Action
We have been working with partners such as MongoDB, Datadog and HashiCorp to integrate with App Runner. Here is a flavor of what they have been working on:
MongoDB – “We’re excited to integrate App Runner with MongoDB Atlas so that developers can leverage the scalability and performance of our global, cloud-native database service for their App Runner applications.”
Datadog – “Using AWS App Runner, customers can now more easily deploy and scale their web applications from a container image or source code repository. With our new integration, customers can monitor their App Runner metrics, logs, and events to troubleshoot issues faster, and determine the best resource and scaling settings for their app.”
HashiCorp – “Integrating HashiCorp Terraform with AWS App Runner means developers have a faster, easier way to deploy production cloud applications, with less infrastructure to configure and manage.”
We also have exciting integrations from Pulumi, Logz.io, and Sysdig, which will allow App Runner customers to use the tools and service they already know and trust. As an AWS Consulting Partner, Trek10 can help customers leverage App Runner for cloud-native architecture design.
Availability and Pricing
AWS App Runner is available today in US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), Europe (Ireland). You can use App Runner with the AWS Management Console and AWS Copilot CLI.
With App Runner, you pay for the compute and memory resources used by your application. App Runner automatically scales the number of active containers up and down to meet the processing requirements of your application. You can set a maximum limit on the number of containers your application uses so that costs do not exceed your budget.
You are only billed for App Runner when it is running and you can pause your application easily and resume it quickly. This is particularly useful in development and test situations as you can switch off an application when you are not using it, helping you manage your costs. For more information, see the App Runner pricing page.
Start using AWS App Runner today and run your web applications at scale, quickly and securely.
— Martin