

April updates include API general availability, new guidance articles, dashboard updates, IoT Edge updates, and device connectivity events.
AWS Local Zones Are Now Open in Boston, Miami, and Houston
AWS Local Zones place select AWS services (compute, storage, database, and so forth) close to large population, industry, and IT centers. They support use cases such as real-time gaming, hybrid migrations, and media & entertainment content creation that need single-digit millisecond latency for end-users in a specific geographic area.
Last December I told you about our plans to launch a total of fifteen AWS Local Zones in 2021, and also announced the preview of the Local Zones in Boston, Miami, and Houston. Today I am happy to announce that these three Local Zones are now ready to host your production workloads, joining the existing pair of Local Zones in Los Angeles. As I mentioned in my original post, each Local Zone is a child of a particular parent region, and is managed by the control plane in the region. The parent region for all three of these zones is US East (N. Virginia).
Using Local Zones
To get started, I need to enable the Zone(s) of interest. I can do this from the command line (modify-availability-zone-group), via an API call (ModifyAvailabilityZoneGroup), or from within the EC2 Console. From the console, I enter the parent region and click Zones in the Account attributes:
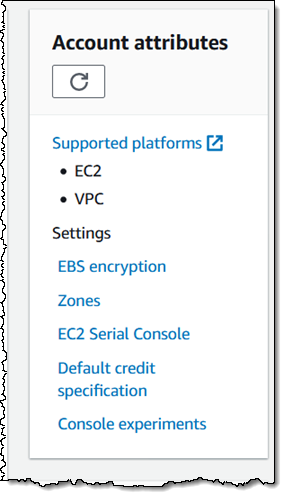
I can see the Local Zones that are within the selected parent region. I click Manage for the desired Local Zone:
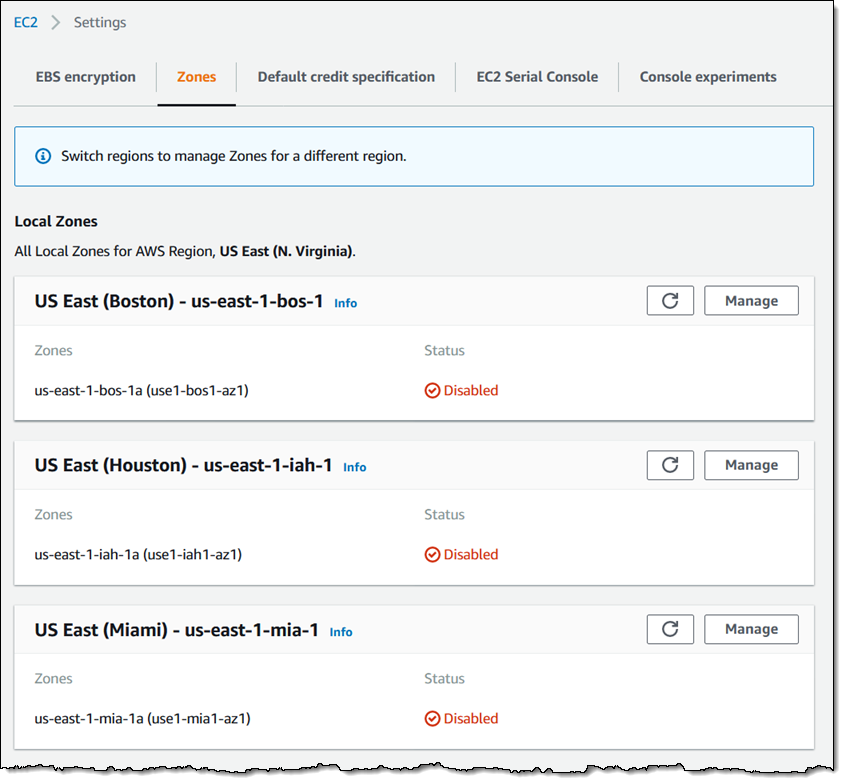
I click Enabled and Update zone group, and I am ready to go!
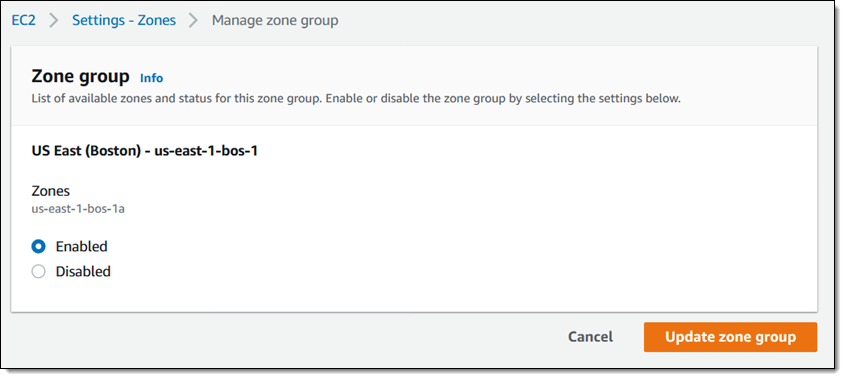
I can create Virtual Private Clouds (VPCs), launch EC2 instances, create SSD-backed EBS volumes (gp2), and set up EKS and ECS clusters in the Local Zone (see the AWS Local Zones Features page for a full list of supported services).
The new Local Zones currently offer the following instances:
| Name | Category | vCPUs | Memory (GiB) |
| t3.xlarge | General Purpose | 4 | 16 |
| c5d.2xlarge | Compute Intensive | 8 | 16 |
| g4dn.2xlarge | GPU | 8 | 32 |
| r5d.2xlarge | Memory Intensive | 8 | 64 |
I can also use EC2 Auto Scaling, AWS CloudFormation, and Amazon CloudWatch in the parent region to monitor and control these resources.
Local Zones in Action
AWS customers are already making great use of all five operational Local Zones! After talking with my colleagues, I learned that the use cases for Local Zones can be grouped into two categories:
Distributed Edge – These customers want to place selected parts of their gaming, social media, and voice assistant applications in multiple, geographically disparate locations in order to deliver a low-latency experience to their users.
Locality – These customers need access to cloud services in specific locations that are in close proximity to their existing branch offices, data centers, and so forth. In addition to low-latency access, they often need to process and store data within a specific geographic region in order to meet regulatory requirements. These customers often run a third party software VPN appliance on Amazon EC2 instance to connect to the desired Local Zone.
Here are a few examples:
Ambra Health provides a cloud-based medical image management suite that empowers some of the largest health systems, radiology practices, and clinical research organizations. The suite replaces traditional desktop image viewers, and uses Local Zones to provide radiologists with rapid access to high quality images so that they can focus on improving patient outcomes.
Couchbase is an award-winning distributed NoSQL cloud database for modern enterprise applications. Couchbase is using AWS Local Zones to provide low latency and single-digit millisecond data access times for applications, ensuring developers’ apps are always available and fast. Using Local Zones, along with Couchbase’s edge computing capabilities, means that their customers are able to store, query, search, and analyze data in real-time
Edgegap is a game hosting service provider focused on providing the best online experience for their customers. AWS Local Zones gives their customers (game development studios such as Triple Hill Interactive, Agog Entertainment, and Cofa Games) the ability to take advantage of ever-growing list of locations and to deploy games with a simple API call.
JackTrip is using Local Zones to allow musicians in multiple locations to collaboratively perform well-synchronized live music over the Internet.
Masomo is an interactive entertainment company that focuses on mobile games including Basketball Arena and Head Ball 2. They use Local Zones to deploy select, latency-sensitive portions of their game servers close to end users, with the goal of improving latency, reducing churn, and providing players with a great experience.
Supercell deploys game servers in multiple AWS regions, and evaluates all new regions as they come online. They are already using Local Zones as deployment targets and considering additional Local Zones as they become available in order to bring the latency-sensitive portions of game servers closer to more end users.
Takeda (a global biopharmaceutical company) is planning to create a hybrid environment that spans multiple scientific centers in and around Boston, with compute-intensive R&D workloads running in the Boston Local Zone.
Ubitus deploys game servers in multiple locations in order to reduce latency and to provide users with a consistent, high-quality experience. They see Local Zones as a (no pun intended) game-changer, and will use it them to deploy and test clusters in multiple cities in pursuit of that consistent experience.
Learn More
Here are some resources to help you learn more about AWS Local Zones:
- Local Zones Overview.
- Local Zones FAQs.
- Local Zones Pricing.
- Local Zones Documentation.
- AWS Now Available from a Local Zone in Los Angeles.
- Announcing a Second Local Zone in Los Angeles.
- In the Works – 3 More AWS Local Zones in 2020, and 12 More in 2021.
Stay Tuned
We are currently working on twelve additional AWS Local Zones (Atlanta, Chicago, Dallas, Denver, Kansas City, Las Vegas, Minneapolis, New York, Philadelphia, Phoenix, Portland, and Seattle) and plan to open them throughout the remainder of 2021. We are also putting plans in place to expand to additional locations, both in the US and elsewhere. If you would like to express your interest in a particular location, please let us know by filling out the AWS Local Zones Interest Form.
Over time we plan to add additional AWS services, including AWS Direct Connect and more EC2 instance types in these new Local Zones, all driven by feedback from our customers.
— Jeff;



![]()
Resolve IT Incidents Faster with Incident Manager, a New Capability of AWS Systems Manager
IT engineers pride themselves on the skill and care they put into building applications and infrastructure. However, as much as we all hate to admit it, there is no such thing as 100% uptime. Everything will fail at some point, often at the worst possible time, leading to many a ruined evening, birthday party, or wedding anniversary (ask me how I know).
As pagers go wild, on-duty engineers scramble to restore service, and every second counts. For example, you need to be able to quickly filter the deluge of monitoring alerts in order to pinpoint the root cause of the incident. Likewise, you can’t afford to waste any time locating and accessing the appropriate runbooks and procedures needed to solve the incident. Imagine yourself at 3:00A.M., wading in a sea of red alerts and desperately looking for the magic command that was “supposed to be in the doc.” Trust me, it’s not a pleasant feeling.
Serious issues often require escalations. Although it’s great to get help from team members, collaboration and a speedy resolution require efficient communication. Without it, uncoordinated efforts can lead to mishaps that confuse or worsen the situation.
Last but not least, it’s equally important to document the incident and how you responded to it. After the incident has been resolved and everyone has had a good night’s sleep, you can replay it, and work to continuously improve your platform and incident response procedures.
All this requires a lot of preparation based on industry best practices and appropriate tooling. Most companies and organizations simply cannot afford to learn this over the course of repeated incidents. That’s a very frustrating way to build an incident preparation and response practice.
Accordingly, many customers have asked us to help them, and today, I’m extremely happy to announce Incident Manager, a new capability of AWS Systems Manager that helps you prepare and respond efficiently to application and infrastructure incidents.
If you can’t wait to try it, please feel free to jump now to the Incident Manager console. If you’d like to learn more, read on!
Introducing Incident Manager in AWS Systems Manager
Since the launch of Amazon.com in 1995, Amazon teams have been responsible for incident response of their services. Over the years, they’ve accumulated a wealth of experience in responding to application and infrastructure issues at any scale. Distilling these years of experience, the Major Incident Management team at Amazon has designed Incident Manager to help all AWS customers prepare for and resolve incidents faster.
As preparation is key, Incident Manager lets you easily create a collection of incident response resources that are readily available when an alarm goes off. These resources include:
- Contacts: Team members who may be engaged in solving incidents and how to page them (voice, email, SMS).
- Escalation plans: Additional contacts who should be paged if the primary on-call responder doesn’t acknowledge the incident.
- Response plans: Who to engage (contacts and escalation plan), what they should do (the runbook to follow), and where to collaborate (the channel tied to AWS Chatbot).

In short, creating a response plan lets you prepare for incidents in a standardized way, so you can react as soon as they happen and resolve them quicker. Indeed, response plans can be triggered automatically by a Amazon CloudWatch alarm or an Amazon EventBridge event notification of your choice. If required, you can also launch a response plan manually.
When the response plan is initiated, contacts are paged, and a new dashboard is automatically put in place in the Incident Manager console. This dashboard is the point of reference for all things involved in the incident:
- An overview on the incident, so that responders have a quick and accurate summary of the situation.
- CloudWatch metrics and alarm graphs related to the incident.
- A timeline of the incident that lists all events added by Incident Manager, and any custom event added manually by responders.
- The runbook included in the response plan, and its current state of execution. Incident Manager provides a default template implementing triage, diagnosis, mitigation and recovery steps.
- Contacts, and a link to the chat channel.
- The list of related Systems Manager OpsItems.
Here’s a sample dashboard. As you can see, you can easily access all of the above in a single click.

After the incident has been resolved, you can create a post-incident analysis, using a built-in template (based on the one that Amazon uses for Correction of Error), or one that you’ve created. This analysis will help you understand the root cause of the incident and what could have been done better or faster to resolve it.
By reviewing and editing the incident timeline, you can zoom in on specific events and how they were addressed. To guide you through the process, questions are automatically added to the analysis. Answering them will help you focus on potential improvements, and how to add them to your incident response procedures. Here’s a sample analysis, showing some of these questions.
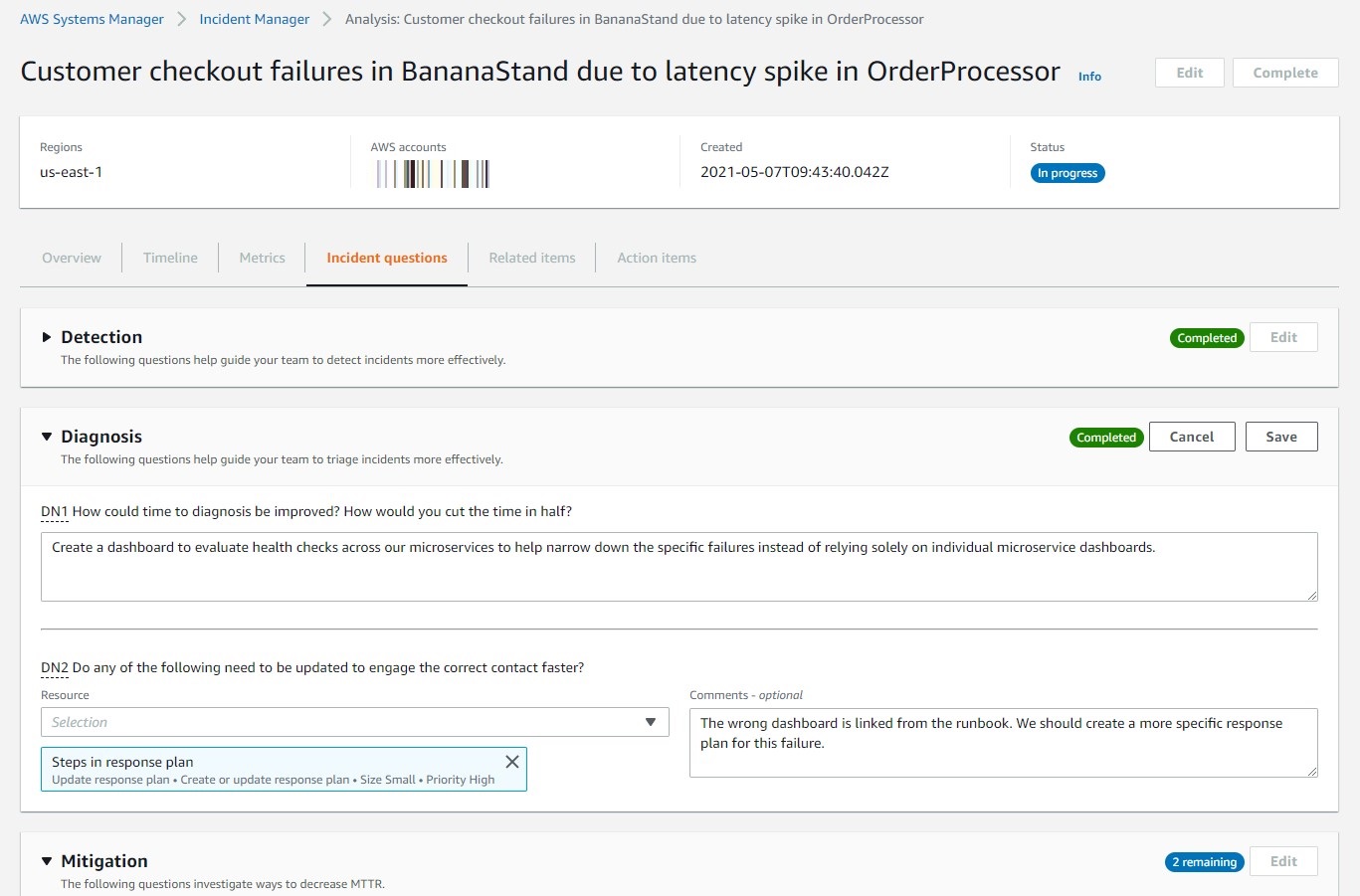
Finally, Incident Manager recommends action items that you can accept or dismiss. If you accept an item, it’s added to a checklist that has to be fully completed before the analysis can be closed. The item is also filed as an OpsItem in AWS Systems Manager OpsCenter, which can sync to ticketing systems like Jira and ServiceNow.
Getting Started
The secret sauce in successfully responding to IT incidents is to prepare, prepare again, and then prepare some more. We encourage you to start planning now for failures that are waiting to happen. When that pager alarm comes in at 3:00AM, it will make a world of difference.
We believe Incident Manager will help you resolve incidents faster by improving your preparation, resolution and analysis workflows. It’s available today in the following AWS Regions:
- US East (N. Virginia), US East (Ohio), US West (Oregon)
- Europe (Ireland), Europe (Frankfurt), Europe (Stockholm)
- Asia Pacific (Tokyo), Asia Pacific (Singapore), Asia Pacific (Sydney)
Give it a try, and let us know what you think. As always, we look forward to your feedback. You can send it through your usual AWS Support contacts, or post it on the AWS Forum for AWS Systems Manager.
If you want to learn more about Incident Manager, sign up for the AWS Summit Online event taking place on May 12 and 13, 2021.



![]()
New options to control chat history in unthreaded Google Chat rooms
What’s changing
We’re introducing a new admin control for Google Chat history in unthreaded rooms. With this new control, admins have the option to:
- Set unthreaded room history behavior separately from 1:1 and group conversations: Admins can set the default history state to be either on or off. They can also prevent users from changing the default history setting for unthreaded rooms. Note: this setting does not impact threaded rooms. Threaded room history is always on.
Note that this will only affect organizations that use Chat; it will not impact organizations that still use classic Hangouts. Use our Help Center to learn more about these changes and how they might impact your organization.
Who’s impacted
Admins
Why you’d use it
These new options give you as an Admin more control and flexibility in setting Chat history options for unthreaded rooms.
Getting started
- Admins: This feature will be ON. Visit the Help Center to learn more about setting the default room history for your users.
- End users: There is no end user setting for this feature.
Rollout pace
Rapid Release and Scheduled Release domains: Gradual rollout starting on May 10, 2021. You can set the new Admin console controls when you see them, but it may take a few days before they take effect. This is a one-time delay during the rollout. The settings should work by late May.
Availability
Available to all Google Workspace customers, as well as G Suite Basic and Business customers.
Resources
- Google Workspace Admin Help: Set default room history for users
- Google Workspace Admin Help: Set chat history options for your organization
![]()
General availability: Enable Azure Site Recovery (ASR) while creating Azure Virtual Machines
With ASR, you can now protect your business-critical Azure virtual machines from regional outages at the time of VM creation.
Google Workspace Updates Weekly Recap – May 7, 2021
New updates
There are no new updates to share this week. Please see below for a recap of published announcements.
Previous announcements
The announcements below were published on the Workspace Updates blog earlier this week. Please refer to the original blog posts for complete details.
Google for Education transformation reports window open, available worldwide
The next reporting window for Google for Education transformation reports is now available for K-12 Google Workspace for Education customers worldwide. | Learn more.
“Show Editors” provides more context on changes made in Google Docs
You can now view richer information on the edit history of a particular range of content in Google Docs. | Available to Google Workspace Business Standard, Business Plus, Enterprise Standard, Enterprise Plus, and Education Plus customers. | Learn more.
Improve Google Cloud Search results with Contextual Boost
We’re adding the ability to boost Google Cloud Search results using the Cloud Search Query API for third party data sources. Contextual boost is one of the key ways used to enable search personalization.| Available to Google Cloud Search customers. | Learn more.
Additional admin controls for Google Voice ring groups
Admins can now configure a “fixed order” pattern for their ring groups and change the maximum duration a call should ring before proceeding to the “unanswered call” behavior. | Available to all Google Workspace and G Suite customers with Google Voice standard and premier licenses. | Learn more.
Specify which attributes are available for the Secure LDAP client
Admins can now specify which attributes they’d like to make available for the LDAP Client, such as system, public and private attributes. | Available to Google Workspace Enterprise Standard, Enterprise Plus, Education Fundamentals, and Education Plus, G Suite Enterprise, and Cloud Identity Premium customers. | Learn more.
More options for customizing a charts line and fill styling in Google Sheets
We’ve added more for line and fill customization options for series and series items. | Learn more.
For a recap of announcements in the past six months, check out What’s new in Google Workspace (recent releases).
![]()
Azure Storage — Attribute-based Access Control (ABAC) now available for preview
Attribute-based Access Control (ABAC) is an authorization mechanism that defines access levels based on attributes associated with security principals, resources, requests or the environment. You can now use ABAC in Azure Storage for Blobs and ADLS Gen2 by defining conditions on role-assignments based on resource and request attributes.
Prevent Shared Key authorization for an Azure Storage account
Enhance secure access to Azure Storage accounts with Prevent Shared Key authorization.
More options for customizing a charts line and fill styling in Google Sheets
Quick Summary
We’ve added more for line and fill customization options for series and series items. You can now modify:
- Color
- Opacity
- Line dash styles
- Line thickness
For column-shaped series, we’ve added the ability to add and style borders, a highly requested feature.

Note: these new options are not available for pie charts, however the ability to change pie slice colors and add borders is already available.
We hope these new options help you best display important data and create more impactful reports with Sheets.
Getting started
- Admins: There is no admin control for this feature.
- End users: Visit the Help Center to learn more about adding and editing a chart in Google Sheets.
Rollout pace
- Rapid and Scheduled Release domains: Extended rollout (potentially longer than 15 days for feature visibility) starting on May 7, 2021
Availability
- Available to all Google Workspace customers, as well as G Suite Basic and Business customers
Resources
![]()