

Illumio for Azure Firewall enables organizations to understand application traffic and dependencies and apply consistent protection across environments – limiting exposure, containing breaches, and improving efficiency.
Provide custom Google Meet background images for your users
What’s changing
We’ve heard from our users that having backgrounds that match your brand guidelines are important for visual polish during critical meetings. Now, admins can now provide a set of images for the background replace feature in Google Meet. This will enable users to easily select an image that properly represents their company's specific brand and style.

Getting started
- Admins:
Visit the Help Center to learn more about letting your users change their backgrounds and special effects. Specifically, please refer to the “Set up custom images and “Set image access” instructions to ensure your users can use custom backgrounds. - End users: When enabled by your admin, visit the Help Center to learn more about changing your background in Meet.
Rollout pace
- Rapid Release and Scheduled Release domains: Extended rollout starting on March 14, 2023
Availability
- Available to all Google Workspace customers, as well as legacy G Suite Basic and Business customers
Note: Use this Help Center article to learn more about how to properly set image access so your users can use your custom backgrounds.
Resources
External label for Google Meet participants
What’s changing
“External” labels will be available in Google Meet. Users will see a label in the top-left corner of their meeting screen indicating that participants who are external to the meeting host’s domain have joined the meeting. In the people panel, external participants will be denoted with the same icon.
.png")
Getting started
- Admins: External labels will be on by default and can be configured in the Admin console at Apps > Google Workspace > Google Meet > Google Meet Safety Settings. Visit the Help Center to learn more about managing Meet settings for your users.
- End users: No end user action is required — you’ll see warning labels for external participants when configured by your admin.
Rollout pace
- Rapid Release domains: Full rollout (1–3 days for feature visibility) starting on March 14, 2023
- Scheduled Release domains: Gradual rollout (up to 15 days for feature visibility) starting on March 23, 2023
Availability
- Available to Google Workspace Essentials, Business Starter, Business Standard, Business Plus, Enterprise Essentials, Enterprise Standard, Enterprise Plus, Education Fundamentals, Education Plus, Education Standard, the Teaching and Learning Upgrade, Frontline, and Nonprofits customers
- Not available to users with personal Google Accounts
Resources
New – Use Amazon S3 Object Lambda with Amazon CloudFront to Tailor Content for End Users
With S3 Object Lambda, you can use your own code to process data retrieved from Amazon S3 as it is returned to an application. Over time, we added new capabilities to S3 Object Lambda, like the ability to add your own code to S3 HEAD and LIST API requests, in addition to the support for S3 GET requests that was available at launch.
Today, we are launching aliases for S3 Object Lambda Access Points. Aliases are now automatically generated when S3 Object Lambda Access Points are created and are interchangeable with bucket names anywhere you use a bucket name to access data stored in Amazon S3. Therefore, your applications don’t need to know about S3 Object Lambda and can consider the alias to be a bucket name.
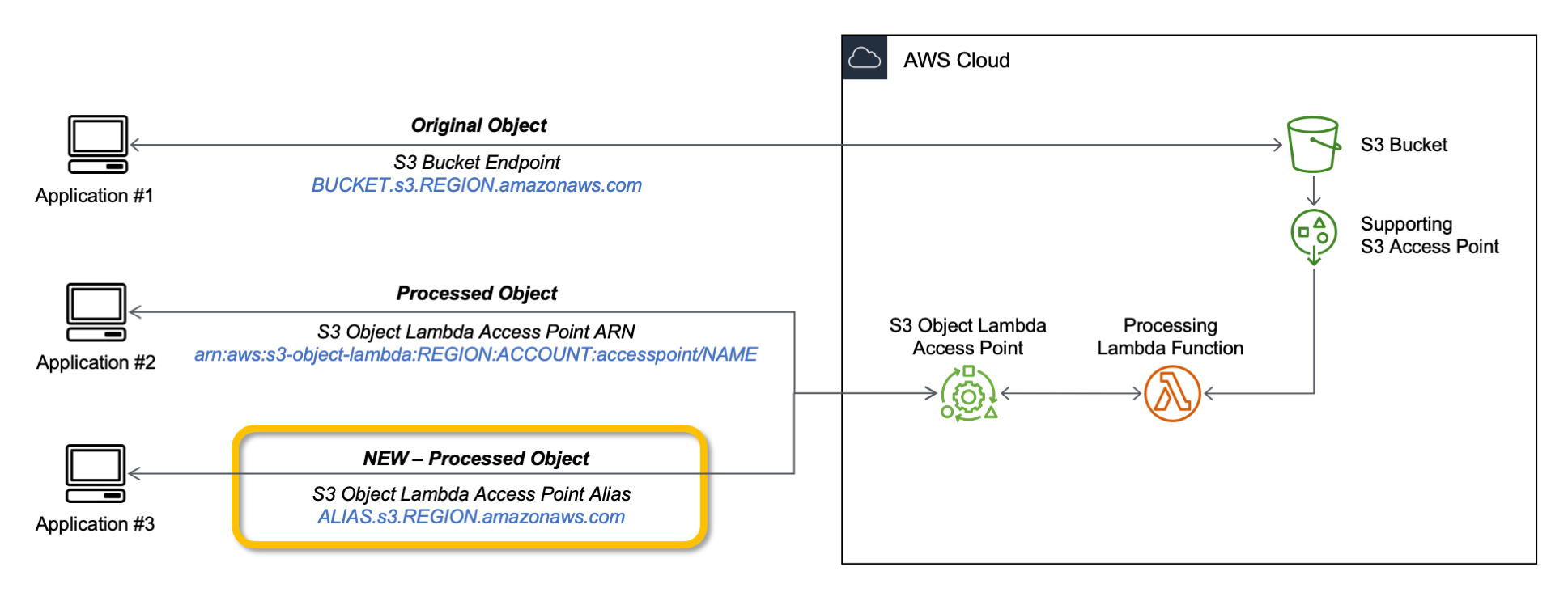
You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to tailor or customize data for end users. You can use this to implement automatic image resizing or to tag or annotate content as it is downloaded. Many images still use older formats like JPEG or PNG, and you can use a transcoding function to deliver images in more efficient formats like WebP, BPG, or HEIC. Digital images contain metadata, and you can implement a function that strips metadata to help satisfy data privacy requirements.
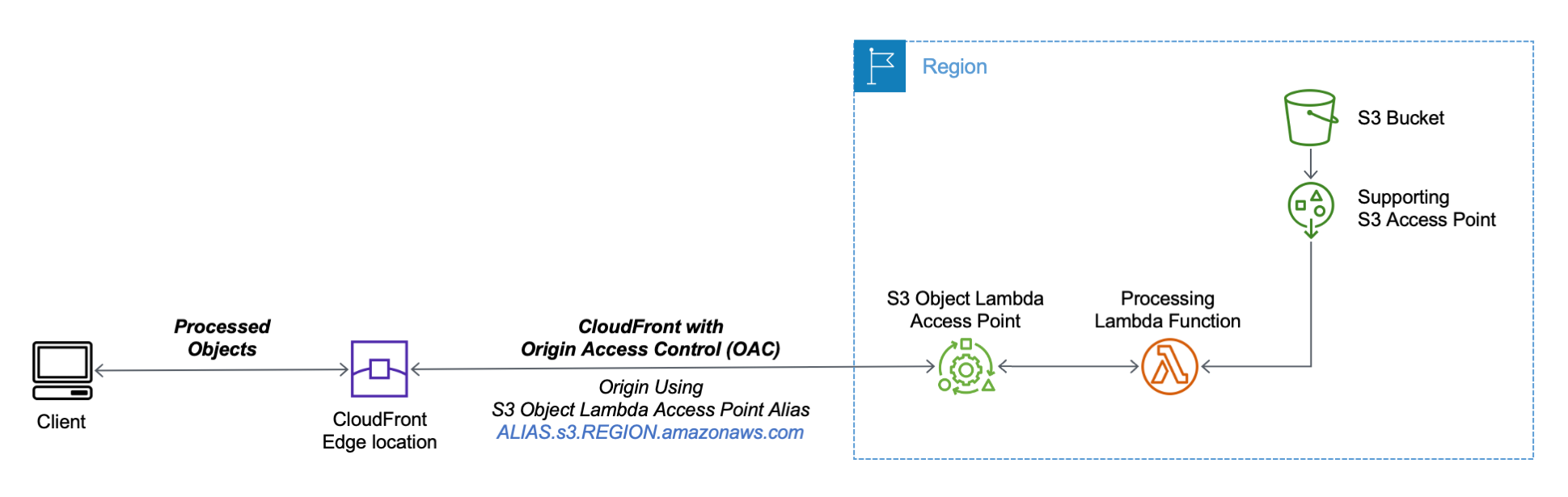
Let’s see how this works in practice. First, I’ll show a simple example using text that you can follow along by just using the AWS Management Console. After that, I’ll implement a more advanced use case processing images.
Using an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
For simplicity, I am using the same application in the launch post that changes all text in the original file to uppercase. This time, I use the S3 Object Lambda Access Point alias to set up a public distribution with CloudFront.
I follow the same steps as in the launch post to create the S3 Object Lambda Access Point and the Lambda function. Because the Lambda runtimes for Python 3.8 and later do not include the requests module, I update the function code to use urlopen from the Python Standard Library:
import boto3
from urllib.request import urlopen
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
response = urlopen(s3_url)
original_object = response.read().decode('utf-8')
# Transform object
transformed_object = original_object.upper()
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_object,
RequestRoute=request_route,
RequestToken=request_token)
returnTo test that this is working, I open the same file from the bucket and through the S3 Object Lambda Access Point. In the S3 console, I select the bucket and a sample file (called s3.txt) that I uploaded earlier and choose Open.

A new browser tab is opened (you might need to disable the pop-up blocker in your browser), and its content is the original file with mixed-case text:
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers...
I choose Object Lambda Access Points from the navigation pane and select the AWS Region I used before from the dropdown. Then, I search for the S3 Object Lambda Access Point that I just created. I select the same file as before and choose Open.

In the new tab, the text has been processed by the Lambda function and is now all in uppercase:
AMAZON SIMPLE STORAGE SERVICE (AMAZON S3) IS AN OBJECT STORAGE SERVICE THAT OFFERS...
Now that the S3 Object Lambda Access Point is correctly configured, I can create the CloudFront distribution. Before I do that, in the list of S3 Object Lambda Access Points in the S3 console, I copy the Object Lambda Access Point alias that has been automatically created:

In the CloudFront console, I choose Distributions in the navigation pane and then Create distribution. In the Origin domain, I use the S3 Object Lambda Access Point alias and the Region. The full syntax of the domain is:
ALIAS.s3.REGION.amazonaws.com
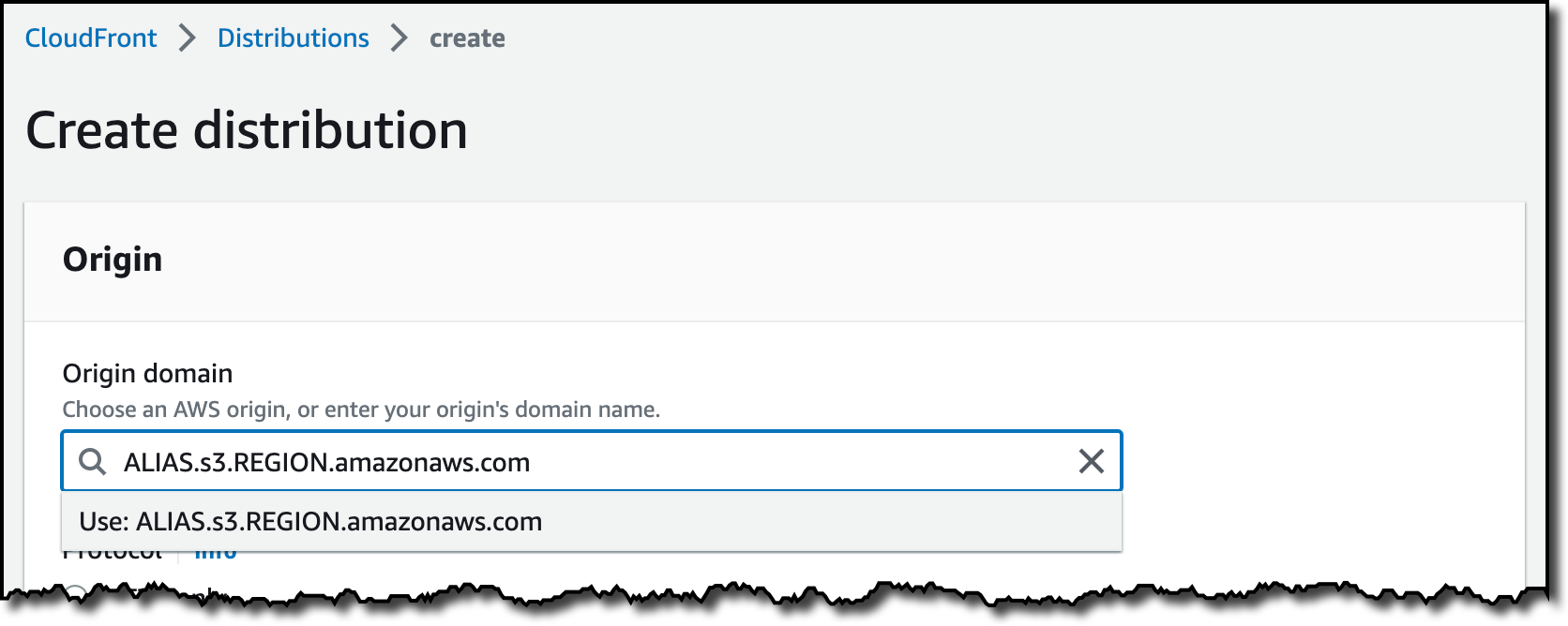
S3 Object Lambda Access Points cannot be public, and I use CloudFront origin access control (OAC) to authenticate requests to the origin. For Origin access, I select Origin access control settings and choose Create control setting. I write a name for the control setting and select Sign requests and S3 in the Origin type dropdown.

Now, my Origin access control settings use the configuration I just created.

To reduce the number of requests going through S3 Object Lambda, I enable Origin Shield and choose the closest Origin Shield Region to the Region I am using. Then, I select the CachingOptimized cache policy and create the distribution. As the distribution is being deployed, I update permissions for the resources used by the distribution.
Setting Up Permissions to Use an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
First, the S3 Object Lambda Access Point needs to give access to the CloudFront distribution. In the S3 console, I select the S3 Object Lambda Access Point and, in the Permissions tab, I update the policy with the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3-object-lambda:Get*",
"Resource": "arn:aws:s3-object-lambda:REGION:ACCOUNT:accesspoint/NAME",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:cloudfront::ACCOUNT:distribution/DISTRIBUTION-ID"
}
}
}
]
}The supporting access point also needs to allow access to CloudFront when called via S3 Object Lambda. I select the access point and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "s3objlambda",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME",
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME/object/*"
],
"Condition": {
"ForAnyValue:StringEquals": {
"aws:CalledVia": "s3-object-lambda.amazonaws.com"
}
}
}
]
}The S3 bucket needs to allow access to the supporting access point. I select the bucket and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "*",
"Resource": [
"arn:aws:s3:::BUCKET",
"arn:aws:s3:::BUCKET/*"
],
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": "ACCOUNT"
}
}
}
]
}Finally, CloudFront needs to be able to invoke the Lambda function. In the Lambda console, I choose the Lambda function used by S3 Object Lambda, and then, in the Configuration tab, I choose Permissions. In the Resource-based policy statements section, I choose Add permissions and select AWS Account. I enter a unique Statement ID. Then, I enter cloudfront.amazonaws.com as Principal and select lambda:InvokeFunction from the Action dropdown and Save. We are working to simplify this step in the future. I’ll update this post when that’s available.
Testing the CloudFront Distribution
When the distribution has been deployed, I test that the setup is working with the same sample file I used before. In the CloudFront console, I select the distribution and copy the Distribution domain name. I can use the browser and enter https://DISTRIBUTION_DOMAIN_NAME/s3.txt in the navigation bar to send a request to CloudFront and get the file processed by S3 Object Lambda. To quickly get all the info, I use curl with the -i option to see the HTTP status and the headers in the response:
It works! As expected, the content processed by the Lambda function is all uppercase. Because this is the first invocation for the distribution, it has not been returned from the cache (x-cache: Miss from cloudfront). The request went through S3 Object Lambda to process the file using the Lambda function I provided.
Let’s try the same request again:
This time the content is returned from the CloudFront cache (x-cache: Hit from cloudfront), and there was no further processing by S3 Object Lambda. By using S3 Object Lambda as the origin, the CloudFront distribution serves content that has been processed by a Lambda function and can be cached to reduce latency and optimize costs.
Resizing Images Using S3 Object Lambda and CloudFront
As I mentioned at the beginning of this post, one of the use cases that can be implemented using S3 Object Lambda and CloudFront is image transformation. Let’s create a CloudFront distribution that can dynamically resize an image by passing the desired width and height as query parameters (w and h respectively). For example:
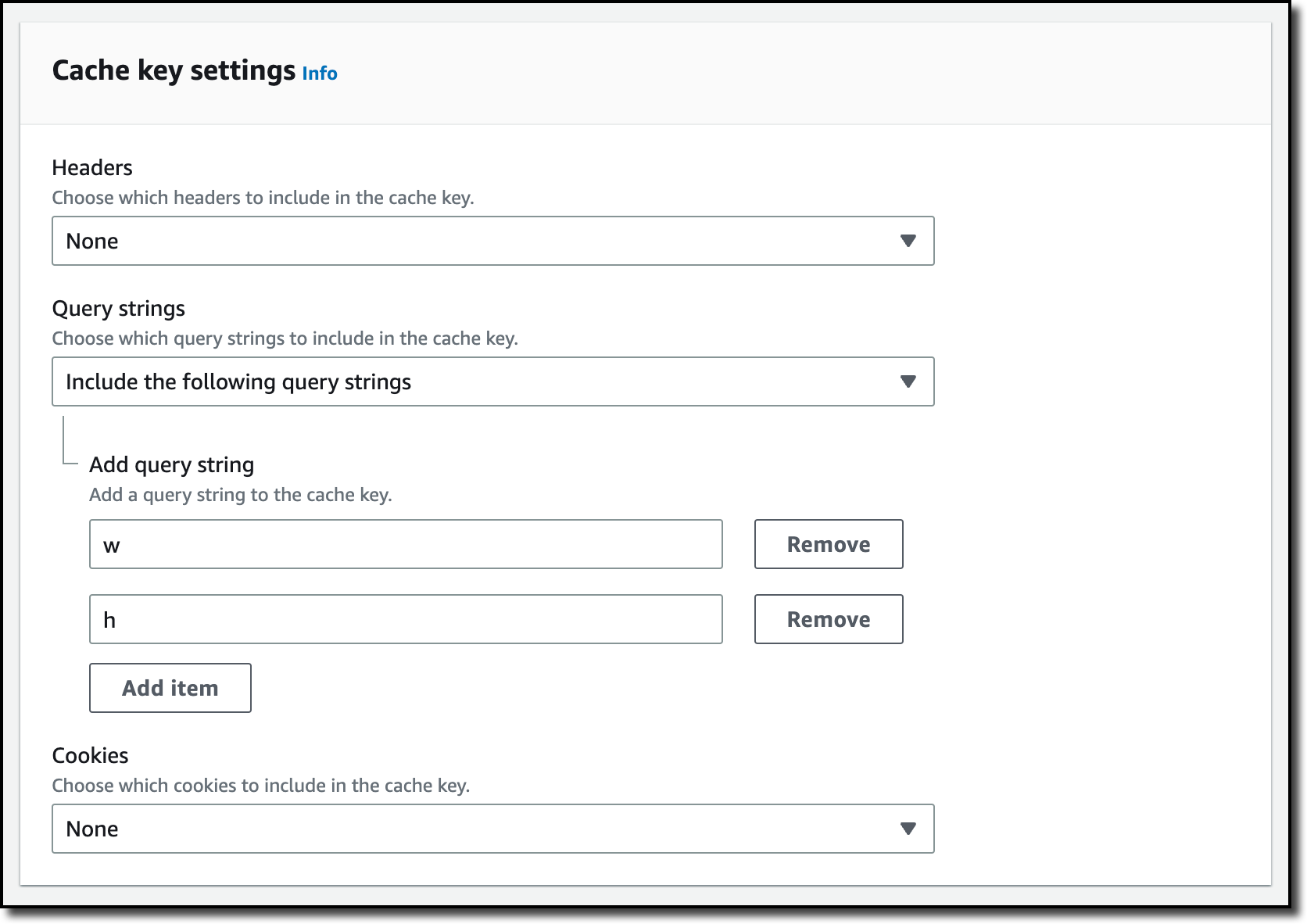
For this setup to work, I need to make two changes to the CloudFront distribution. First, I create a new cache policy to include query parameters in the cache key. In the CloudFront console, I choose Policies in the navigation pane. In the Cache tab, I choose Create cache policy. Then, I enter a name for the cache policy.

In the Query settings of the Cache key settings, I select the option to Include the following query parameters and add w (for the width) and h (for the height).
Then, in the Behaviors tab of the distribution, I select the default behavior and choose Edit.
There, I update the Cache key and origin requests section:
- In the Cache policy, I use the new cache policy to include the
wandhquery parameters in the cache key. - In the Origin request policy, use the
AllViewerExceptHostHeadermanaged policy to forward query parameters to the origin.

Now I can update the Lambda function code. To resize images, this function uses the Pillow module that needs to be packaged with the function when it is uploaded to Lambda. You can deploy the function using a tool like the AWS SAM CLI or the AWS CDK. Compared to the previous example, this function also handles and returns HTTP errors, such as when content is not found in the bucket.
import io
import boto3
from urllib.request import urlopen, HTTPError
from PIL import Image
from urllib.parse import urlparse, parse_qs
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
try:
original_image = Image.open(urlopen(s3_url))
except HTTPError as err:
s3.write_get_object_response(
StatusCode=err.code,
ErrorCode='HTTPError',
ErrorMessage=err.reason,
RequestRoute=request_route,
RequestToken=request_token)
return
# Get width and height from query parameters
user_request = event['userRequest']
url = user_request['url']
parsed_url = urlparse(url)
query_parameters = parse_qs(parsed_url.query)
try:
width, height = int(query_parameters['w'][0]), int(query_parameters['h'][0])
except (KeyError, ValueError):
width, height = 0, 0
# Transform object
if width > 0 and height > 0:
transformed_image = original_image.resize((width, height), Image.ANTIALIAS)
else:
transformed_image = original_image
transformed_bytes = io.BytesIO()
transformed_image.save(transformed_bytes, format='JPEG')
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_bytes.getvalue(),
RequestRoute=request_route,
RequestToken=request_token)
returnI upload a picture I took of the Trevi Fountain in the source bucket. To start, I generate a small thumbnail (200 by 150 pixels).
https://DISTRIBUTION_DOMAIN_NAME/trevi-fountain.jpeg?w=200&h=150

Now, I ask for a slightly larger version (400 by 300 pixels):

It works as expected. The first invocation with a specific size is processed by the Lambda function. Further requests with the same width and height are served from the CloudFront cache.
Availability and Pricing
Aliases for S3 Object Lambda Access Points are available today in all commercial AWS Regions. There is no additional cost for aliases. With S3 Object Lambda, you pay for the Lambda compute and request charges required to process the data, and for the data S3 Object Lambda returns to your application. You also pay for the S3 requests that are invoked by your Lambda function. For more information, see Amazon S3 Pricing.
Aliases are now automatically generated when an S3 Object Lambda Access Point is created. For existing S3 Object Lambda Access Points, aliases are automatically assigned and ready for use.
It’s now easier to use S3 Object Lambda with existing applications, and aliases open many new possibilities. For example, you can use aliases with CloudFront to create a website that converts content in Markdown to HTML, resizes and watermarks images, or masks personally identifiable information (PII) from text, images, and documents.
Customize content for your end users using S3 Object Lambda with CloudFront.
— Danilo
Public preview: Azure Cognitive Service for Vision Powers State-of-the-Art Computer Vision Development
Extract robust insights from images and video content across multiple industry domains
Microsoft Mitigates Outlook Elevation of Privilege Vulnerability
March 24, 2023 update: Impact Assessment has been updated to a link to Guidance for investigating attacks using CVE-2023-23397 – Microsoft Security Blog.
March 23, 2023 update: See Releases for Microsoft Products below for clarification on product changes and defense in depth update availability.
Summary Summary Microsoft Threat Intelligence discovered limited, targeted abuse of a vulnerability in Microsoft Outlook for Windows that allows for new technology LAN manager (NTLM) credential theft to an untrusted network, such as the Internet.
マイクロソフトは Outlook の 特権昇格の脆弱性を緩和します
本ブログは、Microsoft Mitigates Outlook Elevation of Privilege Vulnerability の抄訳版です。最新の情報は原文を参照してください。 2023
AWS Week in Review – March 13, 2023
It seems like only yesterday I was last writing the Week in Review post, at the end of January, and now here we are almost mid-way through March, almost into spring in the northern hemisphere, and close to a quarter way through 2023. Where does time fly?!
Last Week’s Launches
Here’s some of the launches and other news from the past week that I want to bring to your attention:
New AWS Heroes: At the center of the AWS Community around the globe, Heroes share their knowledge and enthusiasm. Welcome to Ananda in Indonesia, and Aidan and Wendy in Australia, our newly announced Heroes!
General Availability of AWS Application Composer: Launched in preview during Dr. Werner Vogel’s re:Invent 2022 keynote, AWS Application Composer is a tool enabling the composition and configuration of serverless applications using a visual design surface. The visual design is backed by an AWS CloudFormation template, making it deployment ready.
What I find particularly cool about Application Composer is that it also works on existing serverless application templates, and round-trips changes to the template made in either a code editor or the visual designer. This makes it ideal for both new developers, and experienced serverless developers with existing applications.
My colleague Channy’s post provides an introduction, and Application Composer is also featured in last Friday’s AWS on Air show, available to watch on-demand.
Get daily feature updates via Amazon SNS: One thing I’ve learned since joining AWS is that the service teams don’t stand still, and are releasing something new pretty much every day. Sometimes, multiple things! This can, however, make it hard to keep up. So, I was interested to read that you can now receive daily feature updates, in email, by subscribing to an Amazon Simple Notification Service (Amazon SNS) topic. As usual, Jeff’s post has all the details you need to get started.
Using up to 10GB of ephemeral storage for AWS Lambda functions: If you use Lambda for Extract-Transform-Load (ETL) jobs, or any data-intensive jobs that require temporary storage of data during processing, you can now configure up to 10GB of ephemeral storage, mounted at /tmp, for your functions in six additional Regions – Asia Pacific (Hyderabad), Asia Pacific (Jakarta), Asia Pacific (Melbourne), Europe (Spain), Europe (Zurich), and Middle East (UAE). More information on using ephemeral storage with Lambda functions can be found in this blog post.
Increased table counts for Amazon Redshift: workloads that require large numbers of tables can now take advantage of using up to 200K tables, avoiding the need to split tables across multiple data warehouses. The updated limit is available to workloads using the ra3.4xlarge, ra3.16xlarge, and dc2.8xlarge node types with Redshift Serverless and data warehouse clusters.
Faster, simpler permissions setup for AWS Glue: Glue is a serverless data integration and ETL service for discovering, preparing, moving, and integrating data intended for use in analytics and machine learning (ML) workloads. A new guided permissions setup process, available in the AWS Management Console, makes it simpler and easier to grant access to AWS Identity and Access Management (IAM) Roles and users to Glue, and use a default role for running jobs and working with notebooks. This simpler, guided approach helps users start authoring jobs, and work with the Data Catalog, without further setup.
Microsoft Active Directory authentication for the MySQL-Compatible Edition of Amazon Aurora: You can now use Active Directory, either with an existing on-premises directory or with AWS Directory Service for Microsoft Active Directory, to authenticate database users when accessing Amazon Aurora MySQL-Compatible Edition instances, helping reduce operational overhead. It also enables you to make use of native Active Directory credential management capabilities to manage password complexities and rotation, helping you stay in step with your compliance and security requirements.
Launch of the 2023 AWS DeepRacer League and new competition structure: The DeepRacer tracks are one of my favorite things to visit and watch at AWS events, so I was happy to learn the new 2023 league is now underway. If you’ve not heard of DeepRacer, it’s the world’s first global racing league featuring autonomous vehicles, enabling developers of all skill levels to not only compete to complete the track in the shortest time but also to advance their knowledge of machine learning (ML) in the process. Along with the new league, there are now more chances to earn achievements and prizes using an all new three-tier competition spanning national and regional races. Racers compete for a chance to win a spot in the World Championship, held at AWS re:Invent, and a $43,000 prize purse. What are you waiting for, start your (ML) engines today!
AWS open-source news and updates: The latest newsletter highlighting open-source projects, tools, and demos from the AWS Community is now available. The newsletter is published weekly, and you can find edition 148 here.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Upcoming AWS Events
Here’s some upcoming events you may be interested in checking out:
AWS Pi Day: March 14th is the third annual AWS Pi Day. Join in with the celebrations of the 17th birthday of Amazon Simple Storage Service (Amazon S3) and the cloud in a live virtual event hosted on the AWS on Air channel. There’ll also be news and discussions on the latest innovations across Data services on AWS, including storage, analytics, AI/ML, and more.
.NET developers and architects looking to modernize their applications will be interested in an upcoming webinar, Modernize and Optimize by Containerizing .NET Applications on AWS, scheduled for March 22nd. In this webinar, you’ll find demonstrations on how you can enhance the security of legacy .NET applications through modernizing to containers, update to a modern version of .NET, and run them on the latest versions of Windows. Registration for the online event is open now.
You can find details on all upcoming events, in-person and virtual, here.
New Livestream Shows
There’s some new livestream shows that launched recently I’d like to bring to your attention:
My colleague Isaac has started a new .NET on AWS show, streaming on Twitch. The second episode was live last week; catch up here on demand. Episode 1 is also available here.
I mentioned AWS on Air earlier in this post, and hopefully you’ve caught our weekly Friday show streaming on Twitch, Twitter, YouTube, and LinkedIn. Or, maybe you’ve seen us broadcasting live from AWS events such as Summits or AWS re:Invent. But did you know that some of the hosts of the shows have recently started their own individual shows too? Check out these new shows below:
- AWS on Air: Startup! – hosted by Jillian Forde, this show focuses on learning technical and business strategies from startup experts to build and scale your startup in AWS. The show runs every Tuesday at 10am PT/1pm ET.
- AWS On Air: Under the Hood with AWS – in this show, host Art Baudo chats with guests, including AWS technical leaders and customers, about Cloud infrastructure. In last week’s show, the discussion centered around Amazon Elastic Compute Cloud (Amazon EC2) Mac Instances. Watch live every Tuesday at 2pm PT/5pm ET.
- AWS on Air: Lockdown! – join host Kyle Dickinson each Tuesday at 11am PT/2pm ET for this show, covering a breadth of AWS security topics in an approachable way that’s suitable for all levels of AWS experience. You’ll encounter demos, guest speakers from AWS, AWS Heroes, and AWS Community Builders.
- AWS on Air: Step up your GameDay – hosts AM Grobelny and James Spencer are joined by special guests to strategize and navigate through an AWS GameDay, a fun and challenge-oriented way to learn about AWS. You’ll find this show every second Wednesday at 11am PT/2pm ET.
- AWS on Air: AMster & the Brit’s Code Corner – join AM Grobelny and myself as we chat about and illustrate cloud development. In Beginners Corner, we answer your questions and try to demystify this strange thing called “coding”, and in Project Corner we tackle slightly larger projects of interest to more experienced developers. There’s something for everyone in Code Corner, live on the 3rd Thursday of each month at 11am PT/2pm ET.
You’ll find all these AWS on Air shows in the published schedule. We hope you can join us!
That’s all for this week – check back next Monday for another AWS Week in Review.
Introducing new Space Manager capabilities in Google Chat
What’s changing
Last year, we announced several improvements to spaces in Google Chat to help you better organize people, topics, and projects, which included introducing the space manager role. Currently, managers can:
- Remove and add participants
- Assign or remove the space manager
- Delete a space
- Delete messages
- Edit the space description
- Update space access from restricted to discoverable or vice versa
Starting today, space managers will now have additional capabilities to ensure effective conversations take place in spaces:
- Space configuration: enables space managers to choose if members can change space details, such as name, icon, description, and guidelines, or turn Chat history on/off for the space.
- Member management: allows space managers to decide if members can add or remove members or groups to a space.
- Conversation moderation: authorizes space managers to determine whether members can use @all in a space.
.png")
Getting started
- Admins: There is no admin control for this feature. Visit the Help Center to learn more about optimizing Chat spaces for your organization.
- End users: Go to the space menu > select “Space settings” > configure space settings and modify permissions as needed. Visit the Help Center to learn more about managing your space settings.
Rollout pace
- Rapid Release domains: Gradual rollout (up to 15 days for feature visibility) starting on March 13, 2023
- Scheduled Release domains: Gradual rollout (up to 15 days for feature visibility) starting on March 27, 2023
Availability
- Available to all Google Workspace customers, as well as legacy G Suite Basic and Business customers
- Not available to users with personal Google Accounts