Since Amazon GuardDuty launched in 2017, GuardDuty has been capable of analyzing tens of billions of events per minute across multiple AWS data sources, such as AWS CloudTrail event logs, Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, and DNS query logs, Amazon Simple Storage Service (Amazon S3) data plane events, Amazon Elastic Kubernetes Service (Amazon EKS) audit logs, and Amazon Relational Database Service (Amazon RDS) login events to protect your AWS accounts and resources.
In 2020, GuardDuty added Amazon S3 protection to continuously monitor and profile S3 data access events and configurations to detect suspicious activities in Amazon S3. Last year, GuardDuty launched Amazon EKS protection to monitor control plane activity by analyzing Kubernetes audit logs from existing and new EKS clusters in your accounts, Amazon EBS malware protection to scan malicious files residing on an EC2 instance or container workload using EBS volumes, and Amazon RDS protection to identify potential threats to data stored in Amazon Aurora databases—recently generally available.
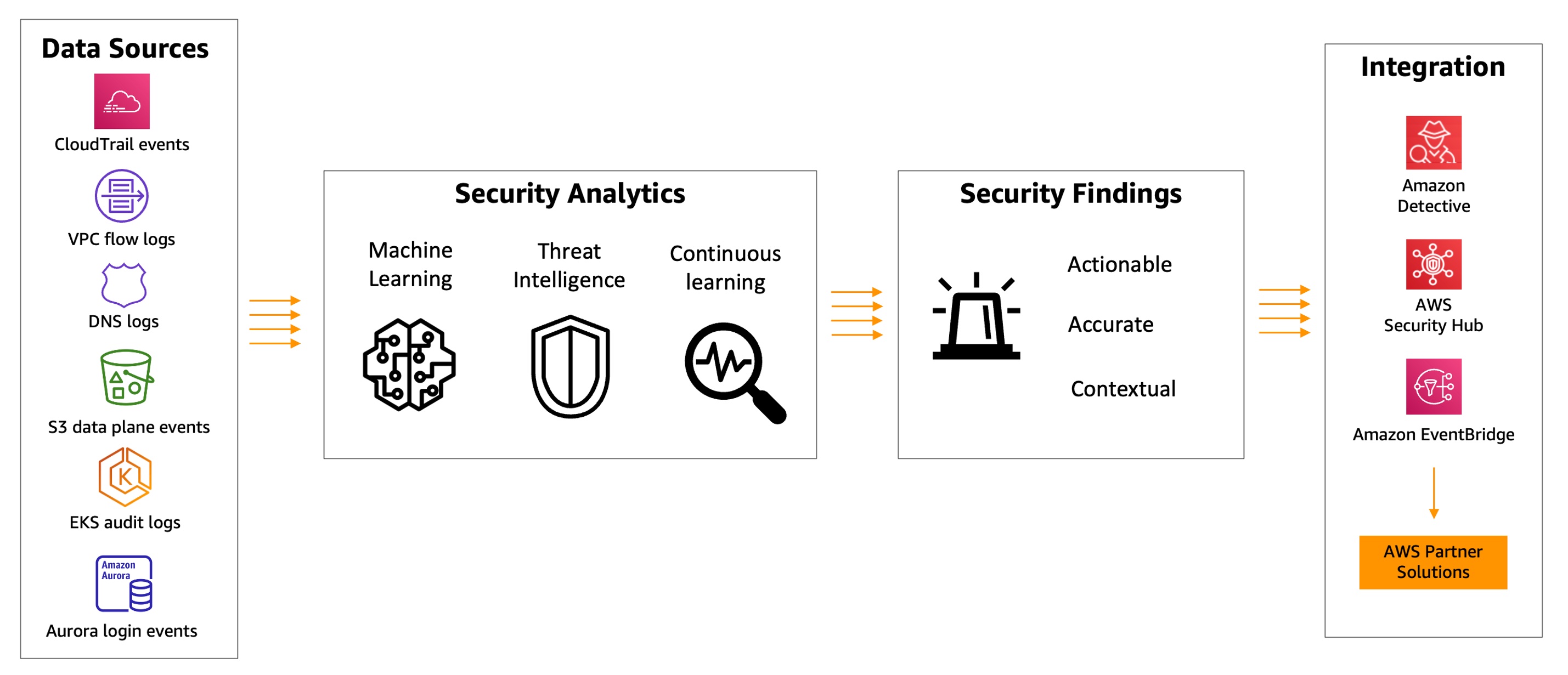
GuardDuty combines machine learning (ML), anomaly detection, network monitoring, and malicious file discovery using various AWS data sources. When threats are detected, GuardDuty automatically sends security findings to AWS Security Hub, Amazon EventBridge, and Amazon Detective. These integrations help centralize monitoring for AWS and partner services, automate responses to malware findings, and perform security investigations from GuardDuty.
Today, we are announcing the general availability of Amazon GuardDuty EKS Runtime Monitoring to detect runtime threats from over 30 security findings to protect your EKS clusters. The new EKS Runtime Monitoring uses a fully managed EKS add-on that adds visibility into individual container runtime activities, such as file access, process execution, and network connections.
GuardDuty can now identify specific containers within your EKS clusters that are potentially compromised and detect attempts to escalate privileges from an individual container to the underlying Amazon EC2 host and the broader AWS environment. GuardDuty EKS Runtime Monitoring findings provide metadata context to identify potential threats and contain them before they escalate.
Configure EKS Runtime Monitoring in GuardDuty
To get started, first enable EKS Runtime Monitoring with just a few clicks in the GuardDuty console.

Once you enable EKS Runtime Monitoring, GuardDuty can start monitoring and analyzing the runtime-activity events for all the existing and new EKS clusters for your accounts. If you want GuardDuty to deploy and update the required EKS-managed add-on for all the existing and new EKS clusters in your account, choose Manage agent automatically. This will also create a VPC endpoint through which the security agent delivers the runtime events to GuardDuty.
If you configure EKS Audit Log Monitoring and runtime monitoring together, you can achieve optimal EKS protection both at the cluster control plane level, and down to the individual pod or container operating system level. When used together, threat detection will be more contextual to allow quick prioritization and response. For example, a runtime-based detection on a pod exhibiting suspicious behavior can be augmented by an audit log-based detection, indicating the pod was unusually launched with elevated privileges.
These options are default, but they are configurable, and you can uncheck one of the boxes in order to disable EKS Runtime Monitoring. When you disable EKS Runtime Monitoring, GuardDuty immediately stops monitoring and analyzing the runtime-activity events for all the existing EKS clusters. If you had configured automated agent management through GuardDuty, this action also removes the security agent that GuardDuty had deployed.
To learn more, see Configuring EKS Runtime Monitoring in the AWS documentation.
Manage GuardDuty Agent Manually
If you want to manually deploy and update the EKS managed add-on, including the GuardDuty agent, per cluster in your account, uncheck Manage agent automatically in the EKS protection configuration.
When managing the add-on manually, you are also responsible for creating the VPC endpoint through which the security agent delivers the runtime events to GuardDuty. In the VPC endpoint console, choose Create endpoint. In the step, choose Other endpoint services for Service category, enter com.amazonaws.us-east-1.guardduty-data for Service name in the US East (N. Virginia) Region, and choose Verify service.
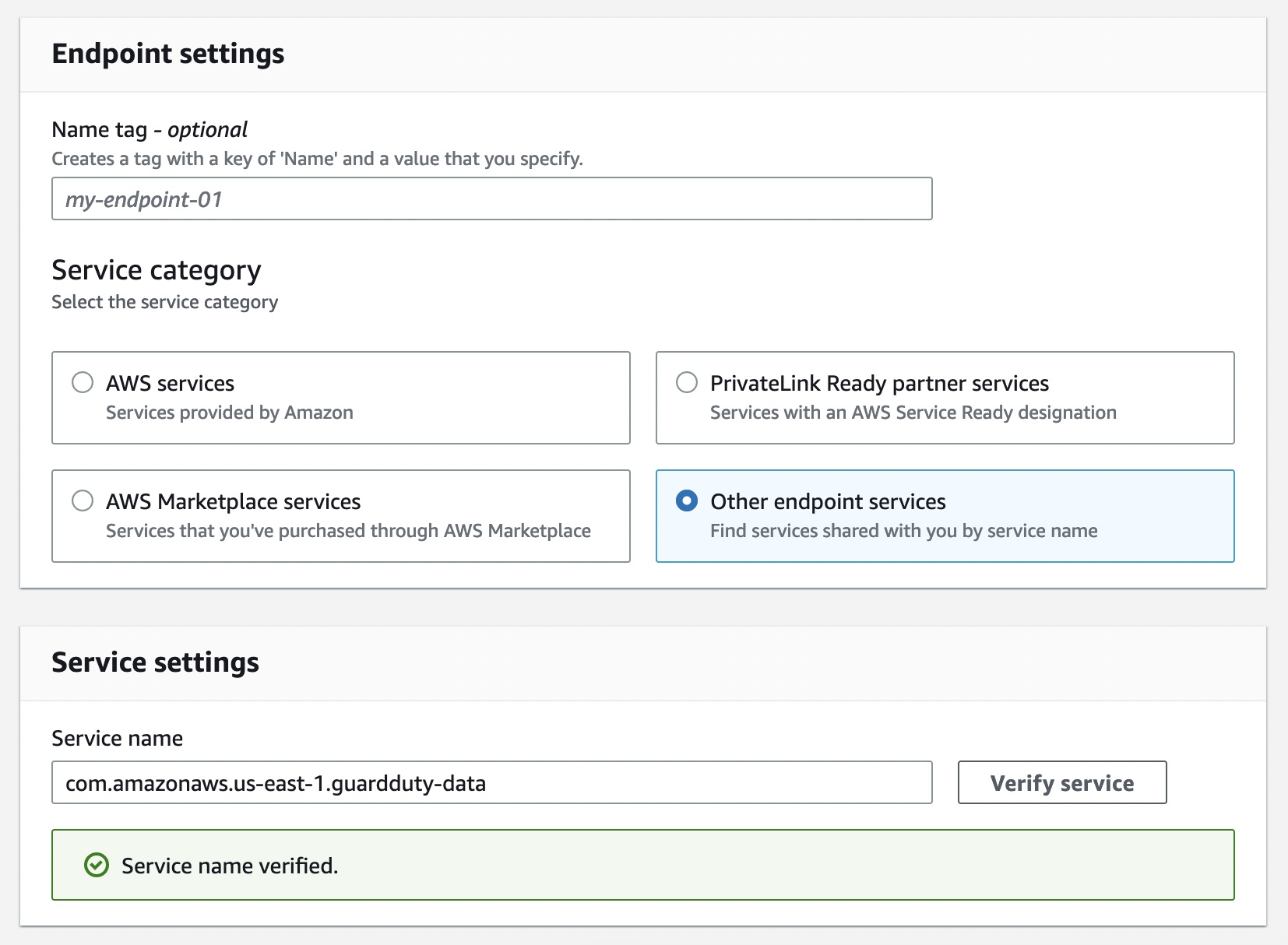
After the service name is successfully verified, choose VPC and subnets where your EKS cluster resides. Under Additional settings, choose Enable DNS name. Under Security groups, choose a security group that has the in-bound port 443 enabled from your VPC (or your EKS cluster).
Add the following policy to restrict VPC endpoint usage to the specified account only:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "*",
"Resource": "*",
"Effect": "Allow",
"Principal": "*"
},
{
"Condition": {
"StringNotEquals": {
"aws:PrincipalAccount": "123456789012"
}
},
"Action": "*",
"Resource": "*",
"Effect": "Deny",
"Principal": "*"
}
]
}Now, you can install the Amazon GuardDuty EKS Runtime Monitoring add-on for your EKS clusters. Select this add-on in the Add-ons tab in your EKS cluster profile on the Amazon EKS console.
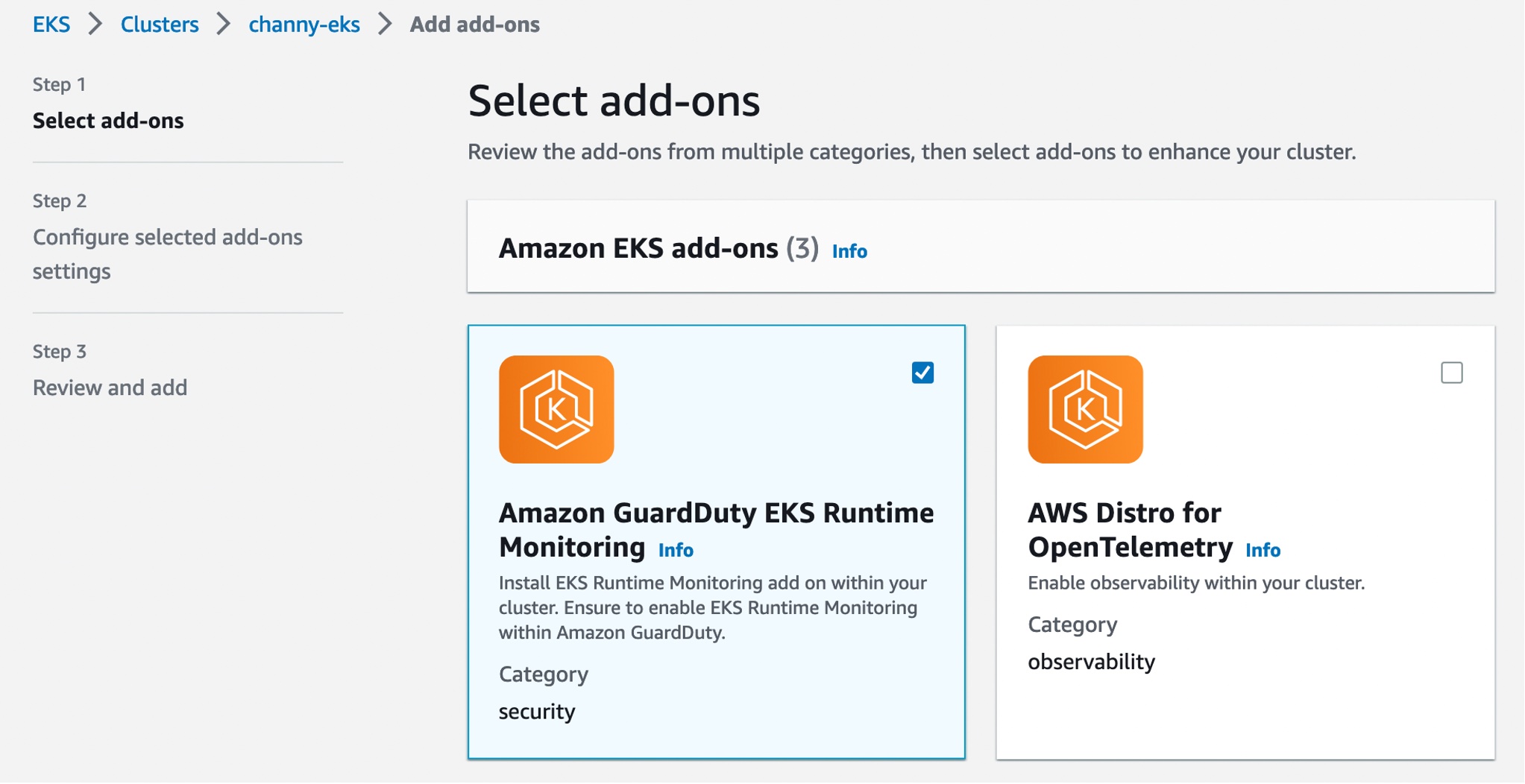
When you enable EKS Runtime Monitoring in GuardDuty and deploy the Amazon EKS add-on for your EKS cluster, you can view the new pods with the prefix aws-guardduty-agent. GuardDuty now starts to consume runtime-activity events from all EC2 hosts and containers in the cluster. GuardDuty then analyzes these events for potential threats.
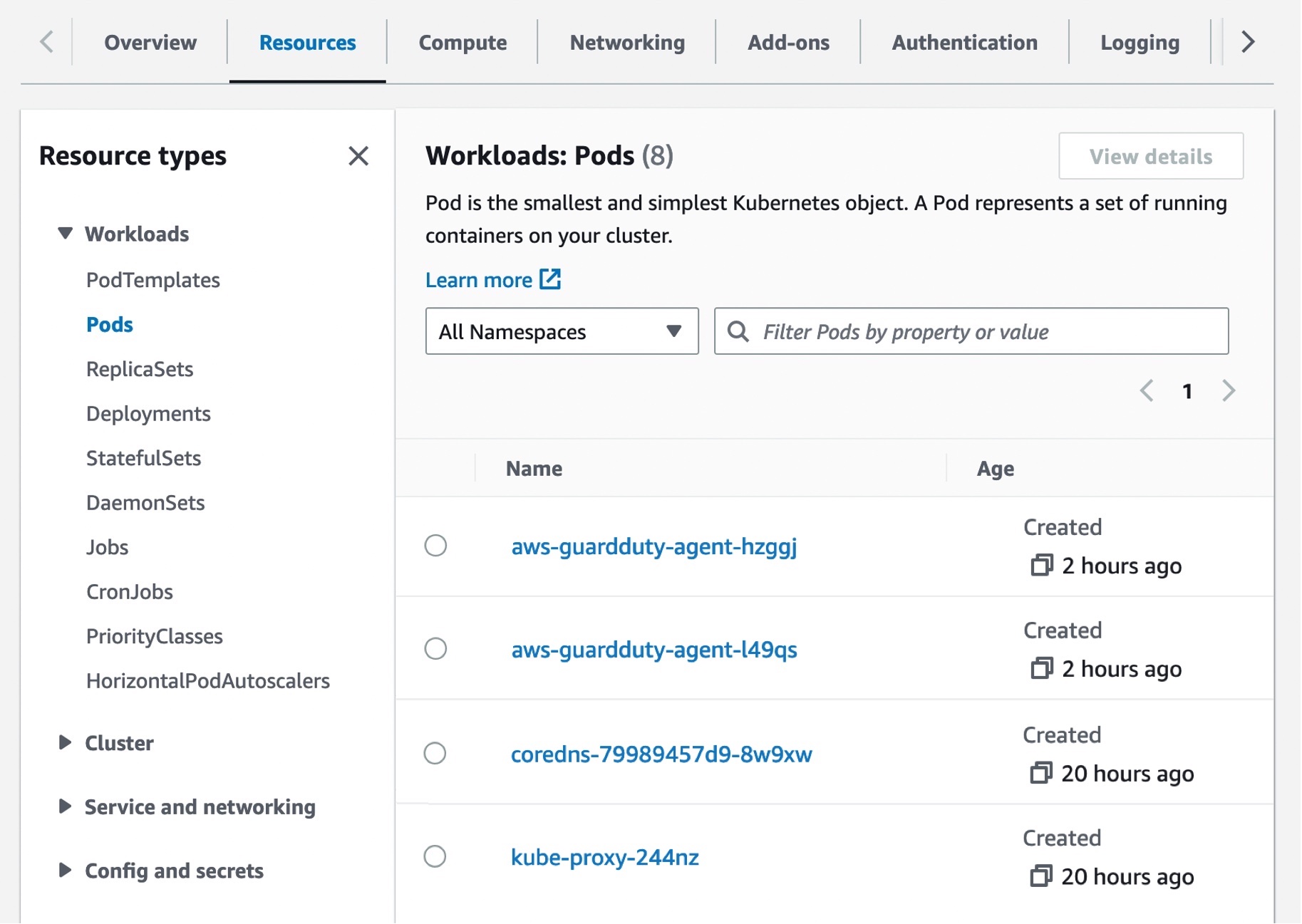
These pods collect various event types and send them to the GuardDuty backend for threat detection and analysis. When managing the add-on manually, you need to go through these steps for each EKS cluster that you want to monitor, including new EKS clusters.
To learn more, see Managing GuardDuty agent manually in the AWS documentation.
Checkout EKS Runtime Security Findings
When GuardDuty detects a potential threat and generates a security finding, you can view the details of the corresponding findings. These security findings indicate either a compromised EC2 instance, container workload, an EKS cluster, or a set of compromised credentials in your AWS environment.
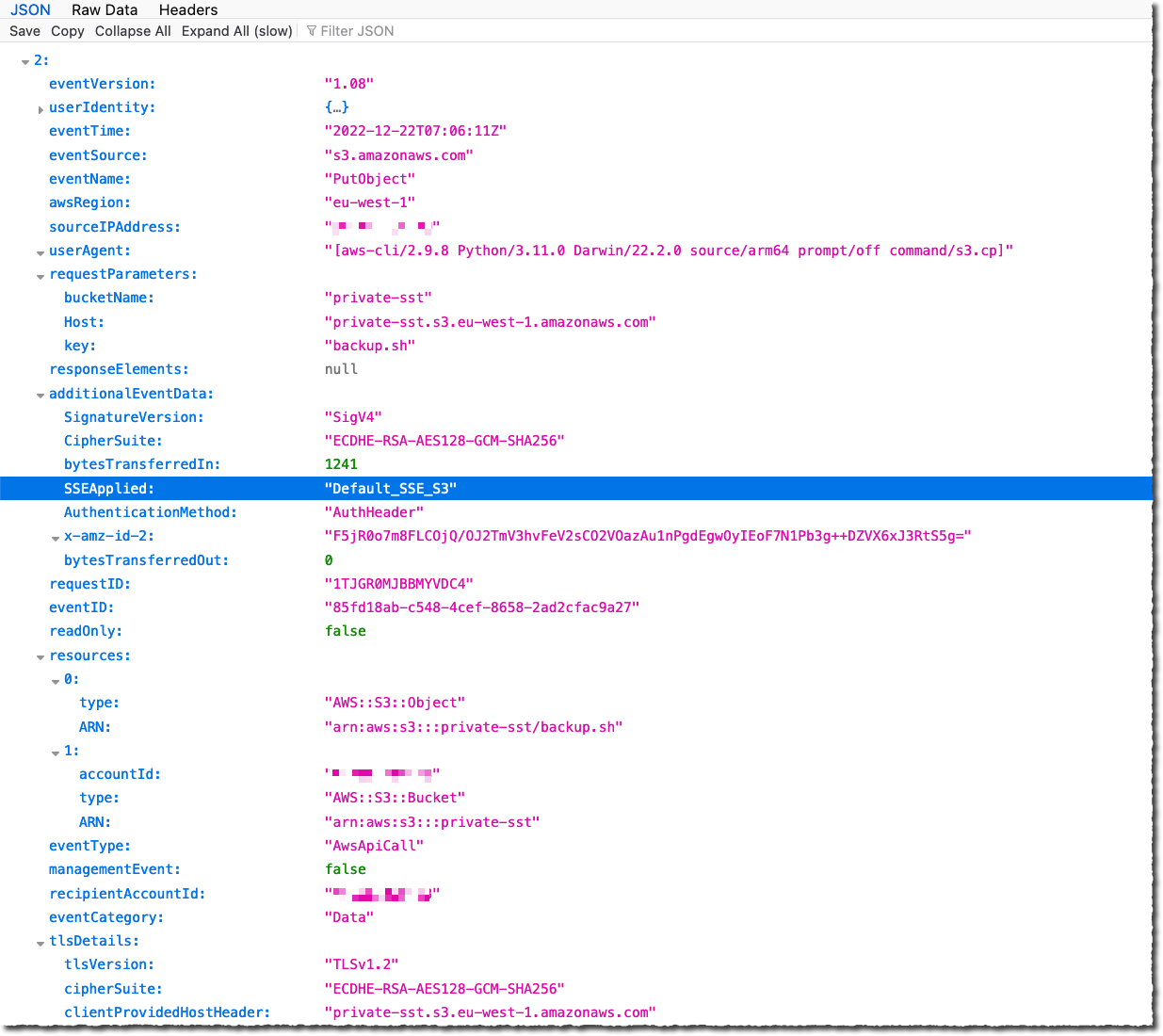
If you want to generate EKS Runtime Monitoring sample findings for testing purposes, see Generating sample findings in GuardDuty in the AWS documentation. Here is an example of potential security issues: a newly created or recently modified binary file in an EKS cluster has been executed.

The ResourceType for an EKS Protection finding type could be an Instance, EKSCluster, or Container. If the Resource type in the finding details is EKSCluster, it indicates that either a pod or a container inside an EKS cluster is potentially compromised. Depending on the potentially compromised resource type, the finding details may contain Kubernetes workload details, EKS cluster details, or instance details.

The Runtime details such as process details and any required context describe information about the observed process, and the runtime context describes any additional information about the potentially suspicious activity.

To remediate a compromised pod or container image, see Remediating EKS Runtime Monitoring findings in the AWS documentation. This document describes the recommended remediation steps for each resource type. To learn more about security finding types, see GuardDuty EKS Runtime Monitoring finding types in the AWS documentation.
Now Available
You can now use Amazon GuardDuty for EKS Runtime Monitoring. For a full list of Regions where EKS Runtime Monitoring is available, visit region-specific feature availability.
The first 30 days of GuardDuty for EKS Runtime Monitoring are available at no additional charge for existing GuardDuty accounts. If you enabled GuardDuty for the first time, EKS Runtime Monitoring is not enabled by default, and needs to be enabled as described above. After the trial period ends in the GuardDuty, you can see the estimated cost of EKS Runtime Monitoring. To learn more, see the GuardDuty pricing page.
For more information, see the Amazon GuardDuty User Guide and send feedback to AWS re:Post for Amazon GuardDuty or through your usual AWS support contacts.
– Channy