

AWS Pi Day 2023 is live today starting at 13:00 PDT; join us on the AWS on Air channel on Twitch.
On this day 17 years ago, we launched a very simple object storage service. It allowed developers to create, list, and delete private storage spaces (known as buckets), upload and download files, and manage their access permissions. The service was available only through a REST and SOAP API. It was designed to provide highly durable data storage with 99.999999999 percent data durability (that’s 11 nines!).
Fast forward to 2023, Amazon Simple Storage Service (Amazon S3) holds more than 280 trillion objects and averages over 100 million requests per second. To protect data integrity, Amazon S3 performs over four billion checksum computations per second. Over the years, we added many capabilities, such as a range of storage classes, to store your colder data cost effectively. Every day, you restore on average more than 1 petabyte from the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive storage classes. Since launch, you have saved $1 billion from using Amazon S3 Intelligent-Tiering. In 2015, we added the possibility of replicating your data across Regions. Every week, Amazon S3 Replication moves more than 100 petabytes of data. Amazon S3 is also at the core of hundreds of thousands of data lakes. It also has become a critical component of a growing ecosystem of serverless applications. Every day, Amazon S3 sends over 125 billion event notifications to serverless applications. Altogether, Amazon S3 is helping people around the world securely store and extract value from their data.

To celebrate Amazon S3‘s birthday AWS is hosting the AWS Pi Day event for the third consecutive year. This live online event starts at 13:00 PDT today (March 14, 2023) on the AWS On Air channel on Twitch and will feature four hours of fresh educational content from AWS experts. We will discuss not only Amazon S3 best practices, we will also dive into the latest innovations across AWS data services, from storage to analytics and AI/ML. Tune in to learn how to get the most out of your data by making it more secure, available, accessible, and connected, and to help you respond to rapid growth and changing demand. You will also learn how to optimize your data costs, automate your cost savings, eliminate operational complexity, and get new insights from your data. Have a look at the full agenda on the registration page.
At AWS, we innovate on your behalf. During the last few weeks, we announced a 99.99 percent SLA for Amazon MemoryDB for Redis, enhanced I/O multiplexing for Amazon ElastiCache for Redis, and encryption by default for new objects on Amazon S3.
But we are not stopping there, and today we take the occasion of this celebration to announce seven new capabilities across our data services.
Mountpoint for Amazon S3 (alpha release): an open-source file client for Amazon S3
Mountpoint for Amazon S3 is an open-source file client for Amazon S3 that you can install on your compute instance. It translates local file storage API calls to REST API calls on objects in Amazon S3. When using Mountpoint for Amazon S3, data lake applications that access objects using file APIs can achieve high single-instance transfer rates, saving on compute costs.
You can get started with Mountpoint for Amazon S3 by mounting an Amazon S3 bucket at a local mount point on your compute instance. Once mounted, applications read objects as files available locally. Mountpoint for Amazon S3 supports sequential and random read operations on existing S3 objects. It is available to download for Linux operating systems as an alpha release and is not yet intended for production workloads. Instead, we want to collect your feedback early and incorporate your input into the design and implementation. To get started, visit the Mountpoint for Amazon S3 GitHub repo, read the technical launch blog, and share your feedback.
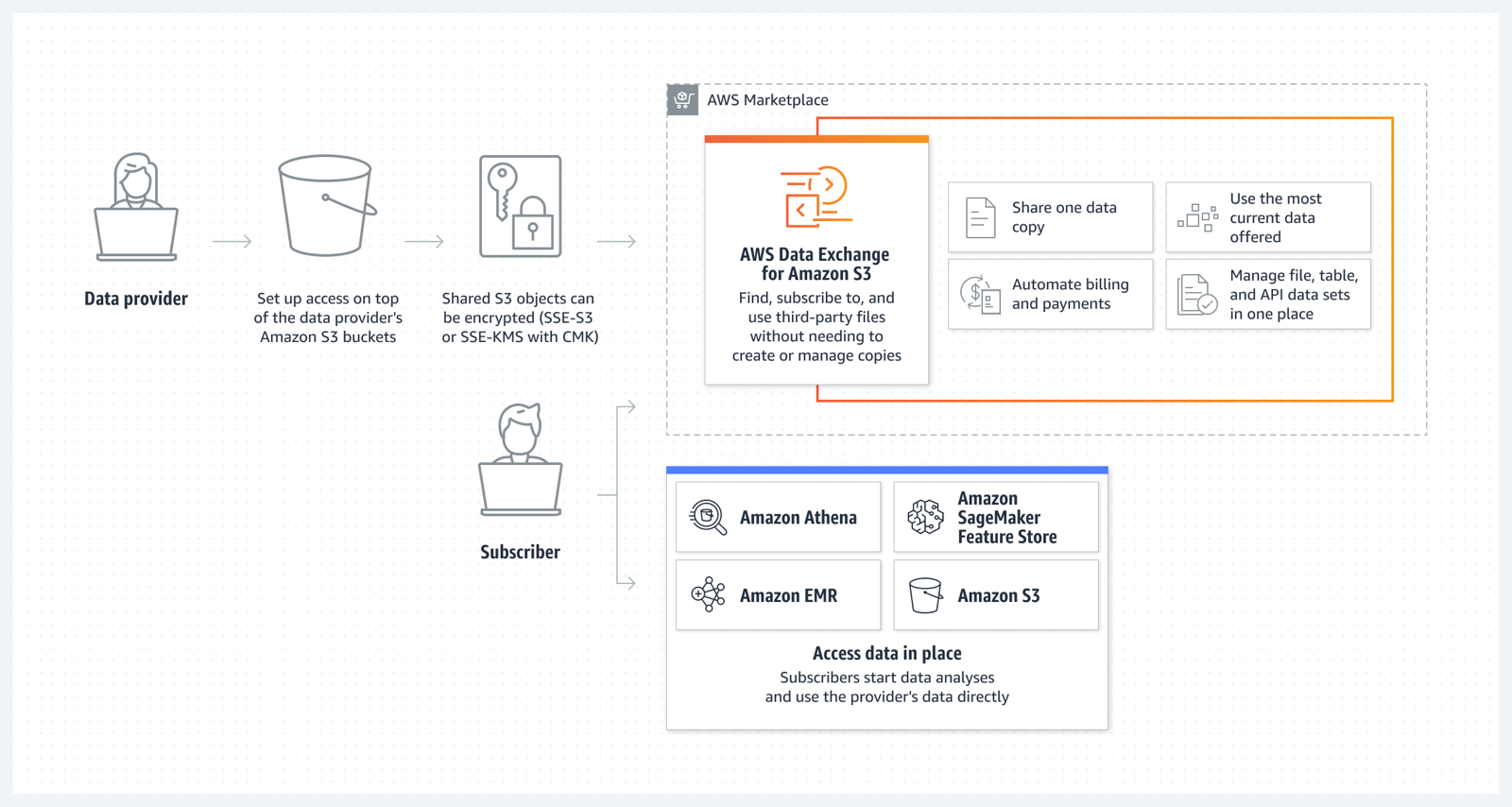
Now Generally Available: AWS Data Exchange for Amazon S3
AWS Data Exchange for Amazon S3 enables you to easily find, subscribe to, and use third-party data files for faster time to insight, storage cost optimization, simplified data licensing management, and more. Data Exchange subscribers can directly use files from data providers’ Amazon S3 buckets for their analysis with AWS services without needing to create or manage copies to their account. Data providers can license in-place access to data hosted in their Amazon S3 buckets.
To learn more about how data providers can simplify and scale access management to multiple data subscribers, you can read this blog.
Amazon S3 Multi-Region Access Points now support replicated datasets that span multiple AWS accounts
We launched Amazon S3 Multi-Region Access Points in September 2021. We added failover control in November 2022. Amazon S3 Multi-Region Access Points now support datasets that are replicated across multiple AWS accounts. Cross-account Multi-Region Access Points simplify object storage access for applications that span both AWS Regions and accounts, avoiding the need for complex request routing logic in your application. They provide a single global endpoint for your multi-Region applications and dynamically route S3 requests based on policies that you define. This helps you to easily implement multi-Region resilience, latency-based routing, and active/passive failover, even when your data is stored in multiple AWS accounts.
You can learn more about S3 Multi-Region Access Points on the Amazon S3 FAQs.
Aliases for S3 Object Lambda Access Points as CloudFront origin
Amazon S3 Object Lambda, launched in March 2021, lets you add your own code to S3 GET, HEAD, and LIST API requests to modify data as it is returned to an application. With today’s launch of aliases for S3 Object Lambda Access Points any application that requires an S3 bucket name can easily present different views of data depending on the requester. You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to modify the data requested. For example, you can dynamically transform an image depending on the device that a user is visiting from, such as a desktop or a smartphone.
If you want to learn more, my colleague Danilo wrote a blog post with more details and code examples.
Simplify private connectivity from on-premises networks
Amazon Virtual Private Cloud (Amazon VPC) interface endpoints for Amazon S3 now offer private DNS options that can help you more easily route Amazon S3 requests to the lowest-cost endpoint in your VPC. With private DNS for Amazon S3, your on-premises applications can use AWS PrivateLink to access Amazon S3 over an interface endpoint, while requests from your in-VPC applications access Amazon S3 using gateway endpoints. Routing requests like this helps you take advantage of the lowest-cost private network path without having to make code or configuration changes to your clients.
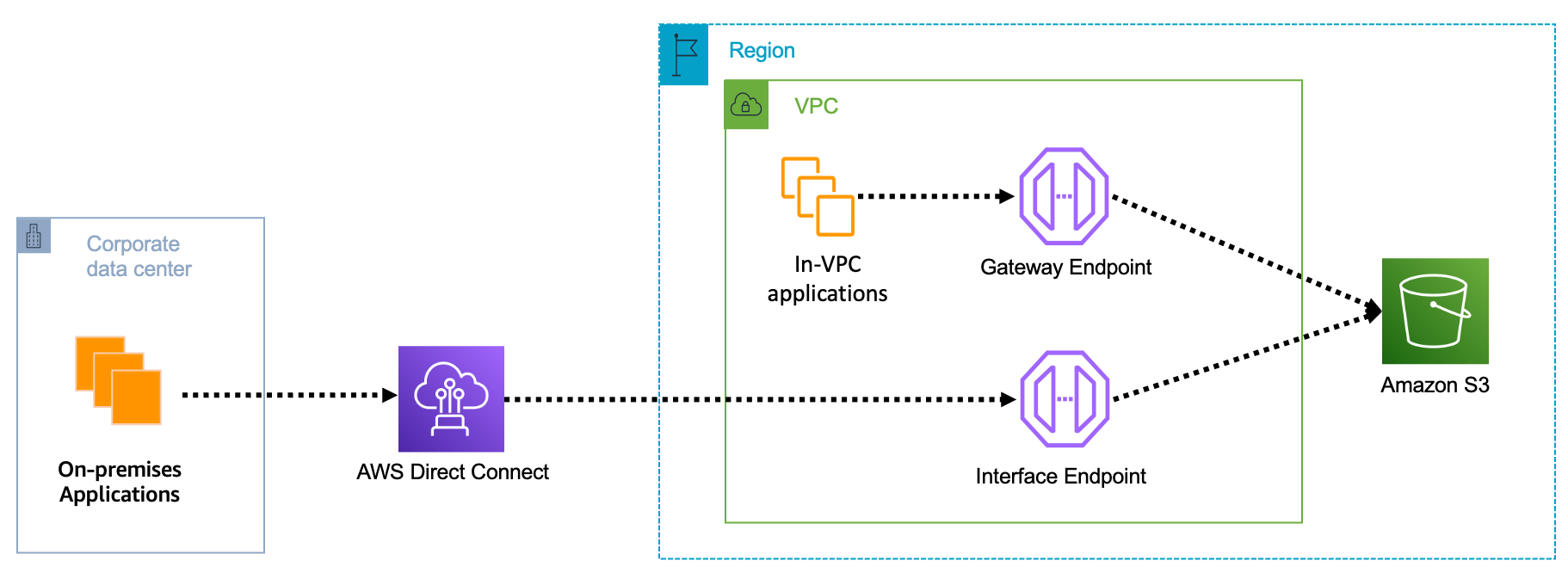
You can learn more on the AWS PrivateLink for Amazon S3 documentation.
Local Amazon S3 Replication on Outposts
Amazon S3 on Outposts now supports S3 replication on Outposts. This extends S3’s fully managed approach to replication to S3 on Outposts buckets. It helps you meet your data residency and data redundancy requirements. With local S3 Replication on Outposts, you can create and configure replication rules to automatically replicate your S3 objects to another Outpost or to another bucket on the same Outpost. During replication, your S3 on Outposts objects are always sent over your local gateway, and objects do not travel back to the AWS Region. S3 Replication on Outposts provides an easy and flexible way to automatically replicate data within a specific data perimeter to address your data redundancy and compliance requirements.
Amazon OpenSearch Security Analytics
The new Amazon OpenSearch Service’s security analytics capability enables your Security Operations (SecOps) teams to detect potential threats quickly while having the tools to help with security investigations on historical data—all with lower data storage costs. Like many other advanced capabilities of Amazon OpenSearch Service, there is no additional charge for security analytics.
You can learn more about Amazon OpenSearch security analytics by reading this blog post.
Join Us Online Today
You will learn more about these launches and about AWS data services in general. We have also prepared some live demos. We designed the AWS Pi Day event for system administrators, engineers, developers, and architects. Our sessions will bring you the latest and greatest information on storage, security, backup, archiving, training and certification, and more.
And to dive deeper, get Pi Day started early by attending AWS Innovate: Data and AI/ML Edition to learn about cutting-edge machine learning tools, strategies for building future-proof applications, and making data-driven decisions for your organization. Don’t miss Swami Sivasubramanian‘s keynote, starting at 9:00 PDT.
Join us today on the AWS Pi Day live stream. Kevin Miller, VP and GM of Amazon S3, will kick off the event with a keynote at 13:00 PDT.
See you there!