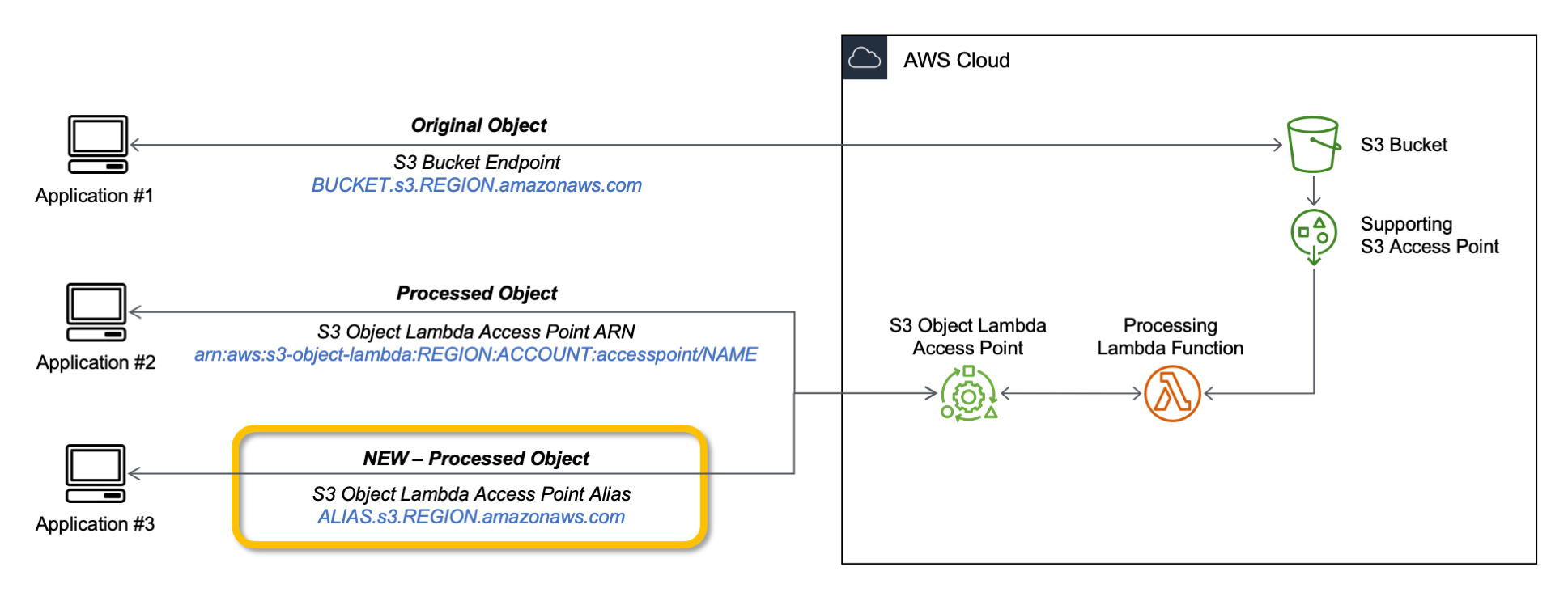
With S3 Object Lambda, you can use your own code to process data retrieved from Amazon S3 as it is returned to an application. Over time, we added new capabilities to S3 Object Lambda, like the ability to add your own code to S3 HEAD and LIST API requests, in addition to the support for S3 GET requests that was available at launch.
Today, we are launching aliases for S3 Object Lambda Access Points. Aliases are now automatically generated when S3 Object Lambda Access Points are created and are interchangeable with bucket names anywhere you use a bucket name to access data stored in Amazon S3. Therefore, your applications don’t need to know about S3 Object Lambda and can consider the alias to be a bucket name.
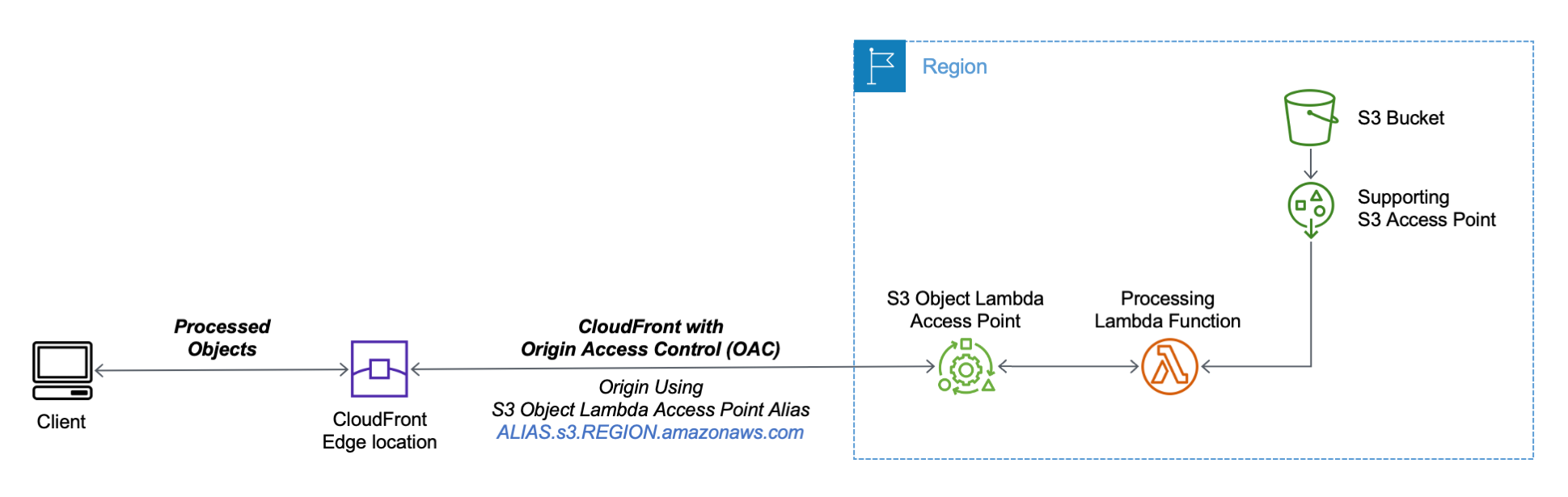
You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to tailor or customize data for end users. You can use this to implement automatic image resizing or to tag or annotate content as it is downloaded. Many images still use older formats like JPEG or PNG, and you can use a transcoding function to deliver images in more efficient formats like WebP, BPG, or HEIC. Digital images contain metadata, and you can implement a function that strips metadata to help satisfy data privacy requirements.
Let’s see how this works in practice. First, I’ll show a simple example using text that you can follow along by just using the AWS Management Console. After that, I’ll implement a more advanced use case processing images.
Using an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
For simplicity, I am using the same application in the launch post that changes all text in the original file to uppercase. This time, I use the S3 Object Lambda Access Point alias to set up a public distribution with CloudFront.
I follow the same steps as in the launch post to create the S3 Object Lambda Access Point and the Lambda function. Because the Lambda runtimes for Python 3.8 and later do not include the requests module, I update the function code to use urlopen from the Python Standard Library:
import boto3
from urllib.request import urlopen
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
response = urlopen(s3_url)
original_object = response.read().decode('utf-8')
# Transform object
transformed_object = original_object.upper()
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_object,
RequestRoute=request_route,
RequestToken=request_token)
returnTo test that this is working, I open the same file from the bucket and through the S3 Object Lambda Access Point. In the S3 console, I select the bucket and a sample file (called s3.txt) that I uploaded earlier and choose Open.

A new browser tab is opened (you might need to disable the pop-up blocker in your browser), and its content is the original file with mixed-case text:
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers...
I choose Object Lambda Access Points from the navigation pane and select the AWS Region I used before from the dropdown. Then, I search for the S3 Object Lambda Access Point that I just created. I select the same file as before and choose Open.

In the new tab, the text has been processed by the Lambda function and is now all in uppercase:
AMAZON SIMPLE STORAGE SERVICE (AMAZON S3) IS AN OBJECT STORAGE SERVICE THAT OFFERS...
Now that the S3 Object Lambda Access Point is correctly configured, I can create the CloudFront distribution. Before I do that, in the list of S3 Object Lambda Access Points in the S3 console, I copy the Object Lambda Access Point alias that has been automatically created:

In the CloudFront console, I choose Distributions in the navigation pane and then Create distribution. In the Origin domain, I use the S3 Object Lambda Access Point alias and the Region. The full syntax of the domain is:
ALIAS.s3.REGION.amazonaws.com
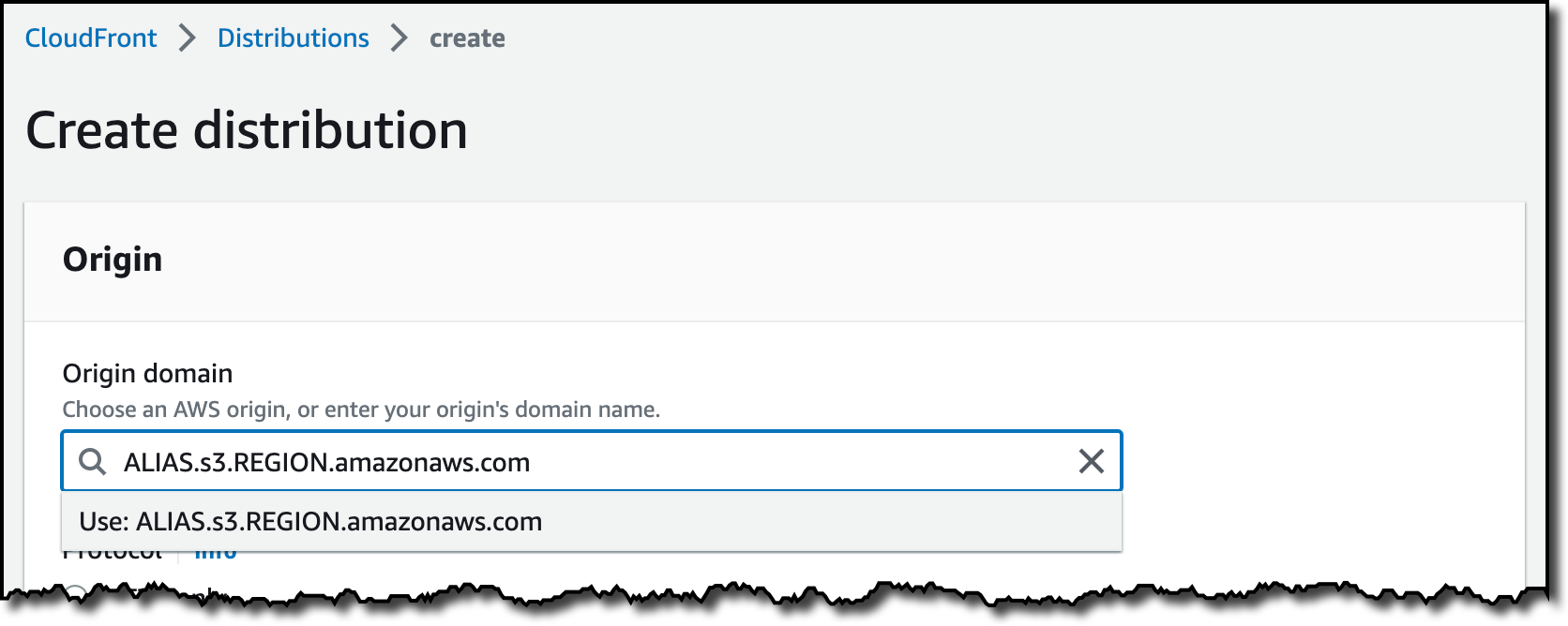
S3 Object Lambda Access Points cannot be public, and I use CloudFront origin access control (OAC) to authenticate requests to the origin. For Origin access, I select Origin access control settings and choose Create control setting. I write a name for the control setting and select Sign requests and S3 in the Origin type dropdown.

Now, my Origin access control settings use the configuration I just created.

To reduce the number of requests going through S3 Object Lambda, I enable Origin Shield and choose the closest Origin Shield Region to the Region I am using. Then, I select the CachingOptimized cache policy and create the distribution. As the distribution is being deployed, I update permissions for the resources used by the distribution.
Setting Up Permissions to Use an S3 Object Lambda Access Point as the Origin of a CloudFront Distribution
First, the S3 Object Lambda Access Point needs to give access to the CloudFront distribution. In the S3 console, I select the S3 Object Lambda Access Point and, in the Permissions tab, I update the policy with the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3-object-lambda:Get*",
"Resource": "arn:aws:s3-object-lambda:REGION:ACCOUNT:accesspoint/NAME",
"Condition": {
"StringEquals": {
"aws:SourceArn": "arn:aws:cloudfront::ACCOUNT:distribution/DISTRIBUTION-ID"
}
}
}
]
}The supporting access point also needs to allow access to CloudFront when called via S3 Object Lambda. I select the access point and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "s3objlambda",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME",
"arn:aws:s3:REGION:ACCOUNT:accesspoint/NAME/object/*"
],
"Condition": {
"ForAnyValue:StringEquals": {
"aws:CalledVia": "s3-object-lambda.amazonaws.com"
}
}
}
]
}The S3 bucket needs to allow access to the supporting access point. I select the bucket and update the policy in the Permissions tab:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "*",
"Resource": [
"arn:aws:s3:::BUCKET",
"arn:aws:s3:::BUCKET/*"
],
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": "ACCOUNT"
}
}
}
]
}Finally, CloudFront needs to be able to invoke the Lambda function. In the Lambda console, I choose the Lambda function used by S3 Object Lambda, and then, in the Configuration tab, I choose Permissions. In the Resource-based policy statements section, I choose Add permissions and select AWS Account. I enter a unique Statement ID. Then, I enter cloudfront.amazonaws.com as Principal and select lambda:InvokeFunction from the Action dropdown and Save. We are working to simplify this step in the future. I’ll update this post when that’s available.
Testing the CloudFront Distribution
When the distribution has been deployed, I test that the setup is working with the same sample file I used before. In the CloudFront console, I select the distribution and copy the Distribution domain name. I can use the browser and enter https://DISTRIBUTION_DOMAIN_NAME/s3.txt in the navigation bar to send a request to CloudFront and get the file processed by S3 Object Lambda. To quickly get all the info, I use curl with the -i option to see the HTTP status and the headers in the response:
It works! As expected, the content processed by the Lambda function is all uppercase. Because this is the first invocation for the distribution, it has not been returned from the cache (x-cache: Miss from cloudfront). The request went through S3 Object Lambda to process the file using the Lambda function I provided.
Let’s try the same request again:
This time the content is returned from the CloudFront cache (x-cache: Hit from cloudfront), and there was no further processing by S3 Object Lambda. By using S3 Object Lambda as the origin, the CloudFront distribution serves content that has been processed by a Lambda function and can be cached to reduce latency and optimize costs.
Resizing Images Using S3 Object Lambda and CloudFront
As I mentioned at the beginning of this post, one of the use cases that can be implemented using S3 Object Lambda and CloudFront is image transformation. Let’s create a CloudFront distribution that can dynamically resize an image by passing the desired width and height as query parameters (w and h respectively). For example:
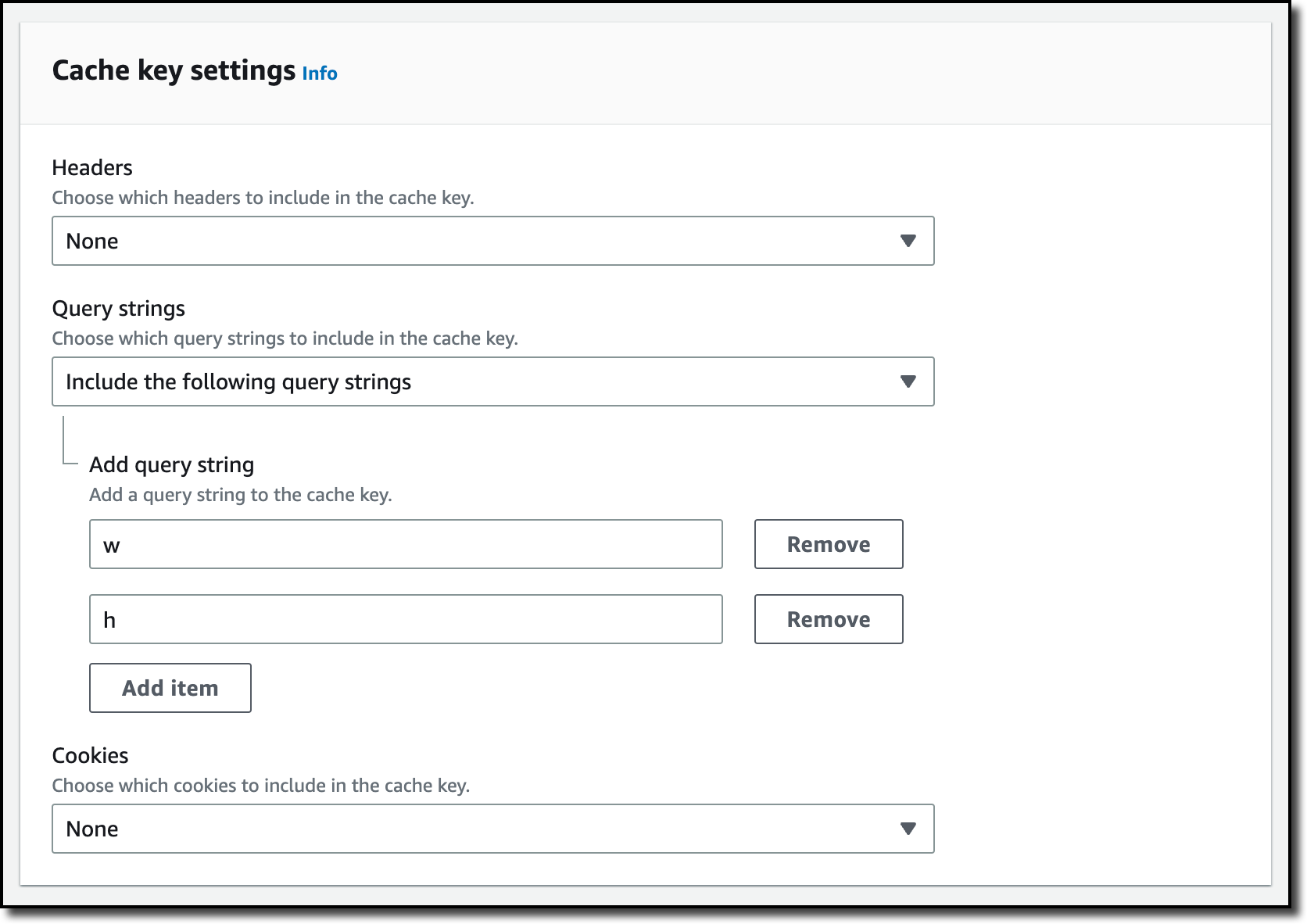
For this setup to work, I need to make two changes to the CloudFront distribution. First, I create a new cache policy to include query parameters in the cache key. In the CloudFront console, I choose Policies in the navigation pane. In the Cache tab, I choose Create cache policy. Then, I enter a name for the cache policy.

In the Query settings of the Cache key settings, I select the option to Include the following query parameters and add w (for the width) and h (for the height).
Then, in the Behaviors tab of the distribution, I select the default behavior and choose Edit.
There, I update the Cache key and origin requests section:
- In the Cache policy, I use the new cache policy to include the
wandhquery parameters in the cache key. - In the Origin request policy, use the
AllViewerExceptHostHeadermanaged policy to forward query parameters to the origin.

Now I can update the Lambda function code. To resize images, this function uses the Pillow module that needs to be packaged with the function when it is uploaded to Lambda. You can deploy the function using a tool like the AWS SAM CLI or the AWS CDK. Compared to the previous example, this function also handles and returns HTTP errors, such as when content is not found in the bucket.
import io
import boto3
from urllib.request import urlopen, HTTPError
from PIL import Image
from urllib.parse import urlparse, parse_qs
s3 = boto3.client('s3')
def lambda_handler(event, context):
print(event)
object_get_context = event['getObjectContext']
request_route = object_get_context['outputRoute']
request_token = object_get_context['outputToken']
s3_url = object_get_context['inputS3Url']
# Get object from S3
try:
original_image = Image.open(urlopen(s3_url))
except HTTPError as err:
s3.write_get_object_response(
StatusCode=err.code,
ErrorCode='HTTPError',
ErrorMessage=err.reason,
RequestRoute=request_route,
RequestToken=request_token)
return
# Get width and height from query parameters
user_request = event['userRequest']
url = user_request['url']
parsed_url = urlparse(url)
query_parameters = parse_qs(parsed_url.query)
try:
width, height = int(query_parameters['w'][0]), int(query_parameters['h'][0])
except (KeyError, ValueError):
width, height = 0, 0
# Transform object
if width > 0 and height > 0:
transformed_image = original_image.resize((width, height), Image.ANTIALIAS)
else:
transformed_image = original_image
transformed_bytes = io.BytesIO()
transformed_image.save(transformed_bytes, format='JPEG')
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Body=transformed_bytes.getvalue(),
RequestRoute=request_route,
RequestToken=request_token)
returnI upload a picture I took of the Trevi Fountain in the source bucket. To start, I generate a small thumbnail (200 by 150 pixels).
https://DISTRIBUTION_DOMAIN_NAME/trevi-fountain.jpeg?w=200&h=150

Now, I ask for a slightly larger version (400 by 300 pixels):

It works as expected. The first invocation with a specific size is processed by the Lambda function. Further requests with the same width and height are served from the CloudFront cache.
Availability and Pricing
Aliases for S3 Object Lambda Access Points are available today in all commercial AWS Regions. There is no additional cost for aliases. With S3 Object Lambda, you pay for the Lambda compute and request charges required to process the data, and for the data S3 Object Lambda returns to your application. You also pay for the S3 requests that are invoked by your Lambda function. For more information, see Amazon S3 Pricing.
Aliases are now automatically generated when an S3 Object Lambda Access Point is created. For existing S3 Object Lambda Access Points, aliases are automatically assigned and ready for use.
It’s now easier to use S3 Object Lambda with existing applications, and aliases open many new possibilities. For example, you can use aliases with CloudFront to create a website that converts content in Markdown to HTML, resizes and watermarks images, or masks personally identifiable information (PII) from text, images, and documents.
Customize content for your end users using S3 Object Lambda with CloudFront.
— Danilo