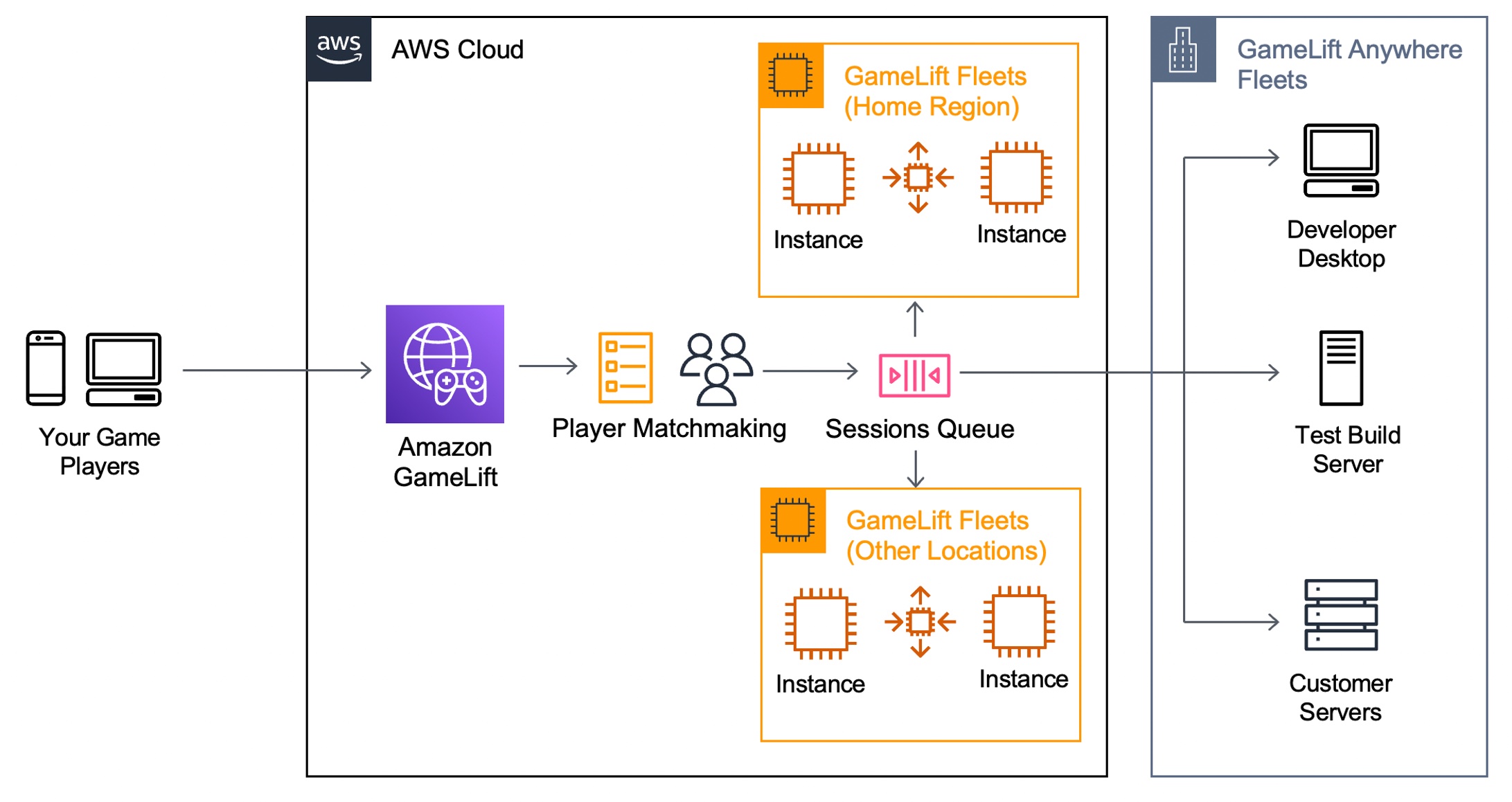
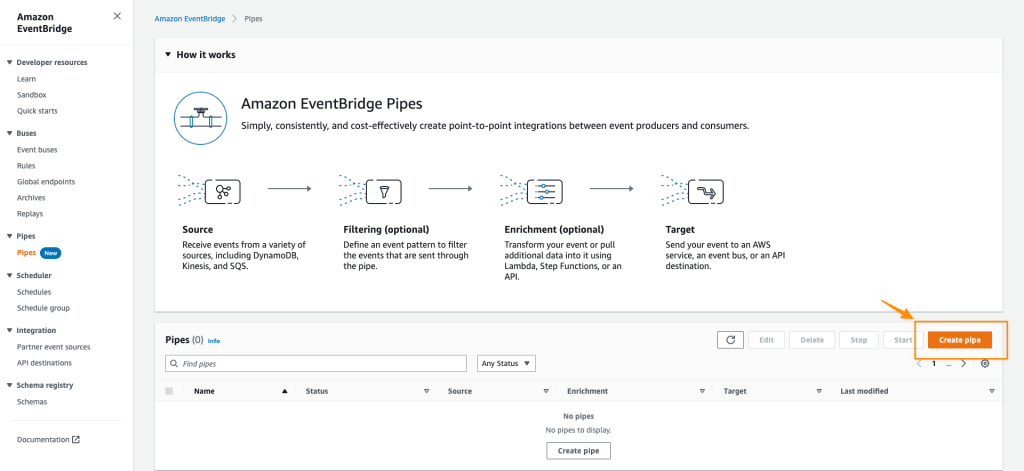
Today, we announced the preview release of Amazon CodeCatalyst. A unified software development and delivery service, Amazon CodeCatalyst enables software development teams to quickly and easily plan, develop, collaborate on, build, and deliver applications on AWS, reducing friction throughout the development lifecycle.
In my time as a developer the biggest excitement—besides shipping software to users—was the start of a new project, or being invited to join a project. Both came with the anticipation of building something cool, cutting new code—seeing an idea come to life. However, starting out was sometimes a slow process. My team or I would need to update our local development environments—or entirely new machines—with tools, libraries, and programming frameworks. We had to create source code repositories and set up other shared tools such as Jira, Confluence, or Jenkins, configure build pipelines and other automation workflows, create test environments, and so on. Day-to-day maintenance of development and build environments consumed valuable team cycles and energy. Collaboration between the team took effort, too, because tools to share information and have a single source of truth were not available. Context switching between projects and dealing with conflicting dependencies in those projects, e.g., Python 3.6 for project X and Python 2.7 for project Y—especially when we had only a single machine to work on—further increased the burden.
It doesn’t seem to have gotten any better! These days, when talking to developers about their experiences, I often hear them express that they feel modern development has become even more complicated. This is due to having to select and configure a wider collection of modern frameworks and libraries, tools, cloud services, continuous integration and delivery pipelines, and many other choices that all need to work together to deliver the application experience. What was once manageable by one developer on one machine is now a sprawling, dynamic, complex net of decisions and tradeoffs, made even more challenging by the need to coordinate all this across dispersed teams.
Enter Amazon CodeCatalyst
I’ve spent some time talking with the team behind Amazon CodeCatalyst about their sources of inspiration and goals. Taking feedback from both new and experienced developers and service teams here at AWS, they examined the challenges typically experienced by teams and individual developers when building software for the cloud. Having gathered and reviewed this feedback, they set about creating a unified tool that smooths out the rough edges that needlessly slow down software delivery, and they added features to make it easier for teams to work together and collaborate. Features in Amazon CodeCatalyst to address these challenges include:
- Blueprints that set up the project’s resources—not just scaffolding for new projects, but also the resources needed to support software delivery and deployment.
- On-demand cloud-based Dev Environments, to make it easy to replicate consistent development environments for you or your teams.
- Issue management, enabling tracing of changes across commits, pull requests, and deployments.
- Automated build and release (CI/CD) pipelines using flexible, managed build infrastructure.
- Dashboards to surface a feed of project activities such as commits, pull requests, and test reporting.
- The ability to invite others to collaborate on a project with just an email.
- Unified search, making it easy to find what you’re looking for across users, issues, code and other project resources.
There’s a lot in Amazon CodeCatalyst that I don’t have space to cover in this post, so I’m going to briefly cover some specific features, like blueprints, Dev Environments, and project collaboration. Other upcoming posts will cover additional features.
Project Blueprints
When I first heard about blueprints, they sounded like a feature to scaffold some initial code for a project. However, they’re much more! Parameterized application blueprints enable you to set up shared project resources to support the application development lifecycle and team collaboration in minutes—not just initial starter code for an application. The resources that a blueprint creates for a project include a source code repository, complete with initial sample code and AWS service configuration for popular application patterns, which follow AWS best practices by default. If you prefer, an external Git repository such as GitHub may be used instead. The blueprint can also add an issue tracker, but external trackers such as Jira can also be used. Then, the blueprint adds a build and release pipeline for CI/CD, which I’ll come to shortly, as well as other integrated tooling.
The project resources and integrated tools set up using blueprints, including the CI/CD pipeline and the AWS resources to host your application, make it so that you can press “deploy” and get sample code running in a few minutes, enabling you to jump right in and start working on your specific business logic.

At launch, customers can choose from blueprints with Typescript, Python, Java, .NET, Javascript for languages and React, Angular, and Vue frameworks, with more to come. And you don’t need to start with a blueprint. You can build projects with workflows that run on anything that works with Linux and Windows operating systems.
Cloud-Based Dev Environments
Development teams can often run into a problem of “environment drift” where one team member has a slightly different version of a toolchain or library compared to everyone else or the test environments. This can introduce subtle bugs that might go unnoticed for some time. Dev Environment specifications, and the other shared resources, that blueprints create help ensure there’s no unnecessary variance, and everyone on the team gets the same setup to provide a consistent, repeatable experience between developers.
Amazon CodeCatalyst uses a devfile to define the configuration of an on-demand, cloud-based Dev Environment, which currently supports four resizable instance size options with 2, 4, 8, or 16 vCPUs. The devfile defines and configures all of the resources needed to code, test, and debug for a given project, minimizing the time the development team members need to spend on creating and maintaining their local development environments. Devfiles, which are added to the source code repository by the selected blueprint can also be modified if required. With Dev Environments, context switching between projects incurs less overhead—with one click, you can simply switch to a different environment, and you’re ready to start working. This means you’re easily able to work concurrently on multiple codebases without reconfiguring. Being on-demand, Dev Environments can also be paused, restarted, or deleted as needed.
Below is an example of a devfile that bootstraps a Dev Environment.
schemaVersion: 2.0.0
metadata:
name: aws-universal
version: 1.0.1
displayName: AWS Universal
description: Stack with AWS Universal Tooling
tags:
- aws
- a12
projectType: aws
commands:
- id: npm_install
exec:
component: aws-runtime
commandLine: "npm install"
workingDir: /projects/spa-app
events:
postStart:
- npm_install
components:
- name: aws-runtime
container:
image: public.ecr.aws/aws-mde/universal-image:latest
mountSources: true
volumeMounts:
- name: docker-store
path: /var/lib/docker
- name: docker-store
volume:
size: 16Gi
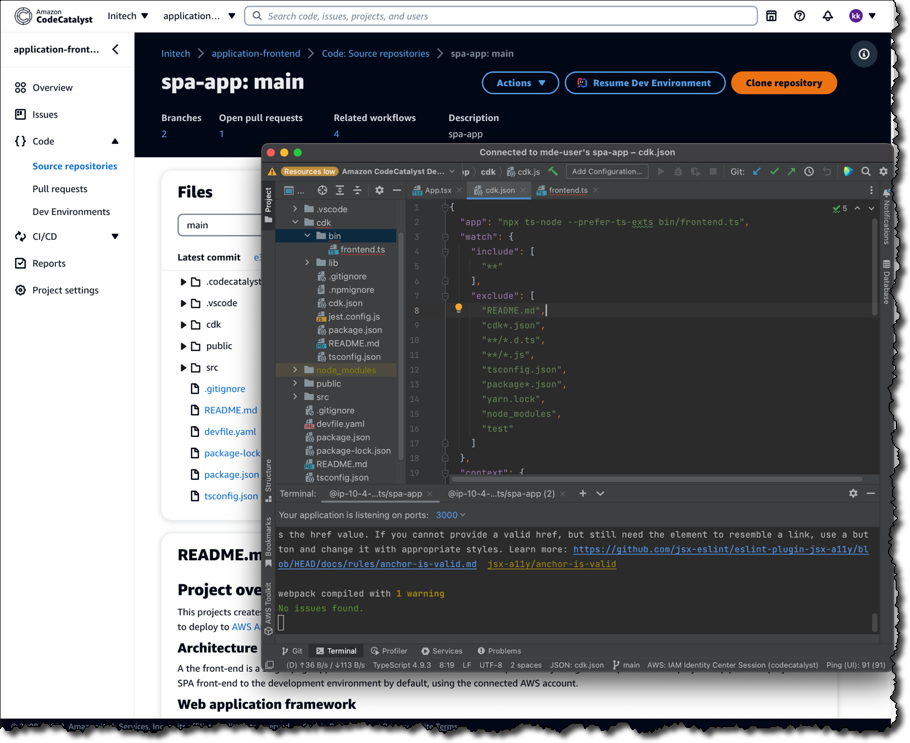
Developers working in cloud-based Dev Environments provisioned by Amazon CodeCatalyst can use AWS Cloud9 as their IDE. However, they can just as easily work with Amazon CodeCatalyst from other IDEs on their local machines, such as JetBrains IntelliJ IDEA Ultimate, PyCharm Pro, GoLand, and Visual Studio Code. Developers can also create Dev Environments from within their IDE, such as Visual Studio Code or for JetBrains using the JetBrains Gateway app. Below, JetBrains IntelliJ is being used.
Build and Release Pipelines
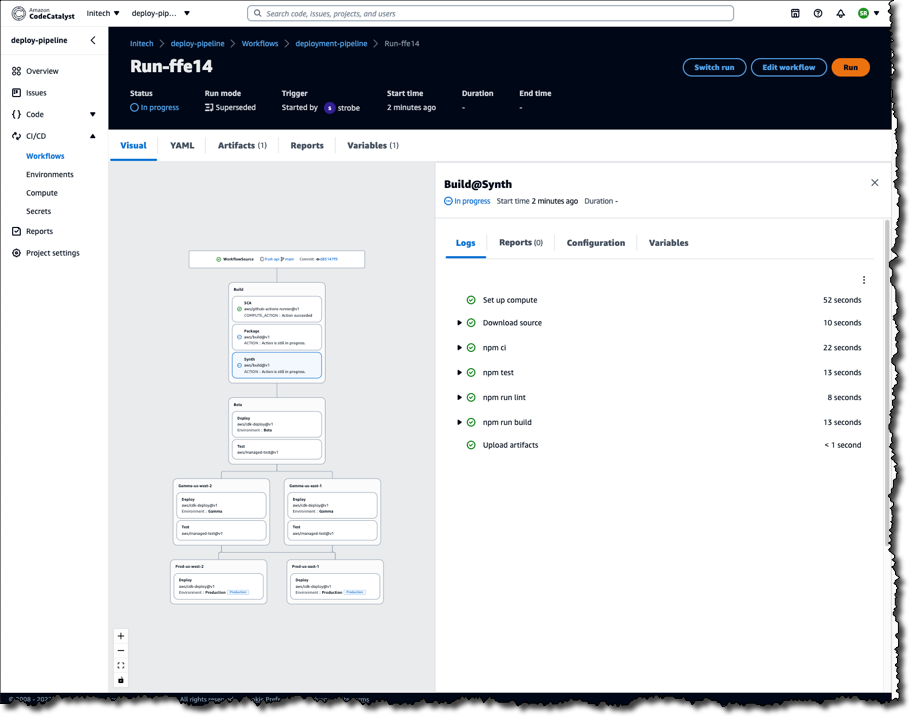
The build and release pipeline created by the blueprint run on flexible, managed infrastructure. The pipelines can use on-demand compute or preprovisioned builds, including a choice of machine sizes, and you can bring your own container environments. You can incorporate build actions that are built in or provided by partners (e.g., Mend, which provides a software composition analysis build action), and you can also incorporate GitHub Actions to compose fully automated pipelines. Pipelines are configurable using either a visual editor or YAML files.
Build and release pipelines enable deployment to popular AWS services, including Amazon Elastic Container Service (Amazon ECS), AWS Lambda, and Amazon Elastic Compute Cloud (Amazon EC2). Amazon CodeCatalyst makes it trivial to set up test and production environments and deploy using pipelines to one or many Regions or even multiple accounts for security.
Project Collaboration
As a unified software development service, Amazon CodeCatalyst not only makes it easier to get started building and delivering applications on AWS, it helps developers of all levels collaborate on projects through a single shared project space and source of truth. Developers can be invited to collaborate using just an email. On accepting the invitation, the developer sees the full project context and can begin work at once using the project’s Dev Environments—no need to spend time updating or reconfiguring their local machine with required tools, libraries, or other pre-requisites.
Existing members of an Amazon CodeCatalyst space, or new members using their email, can be invited to collaborate on a project:
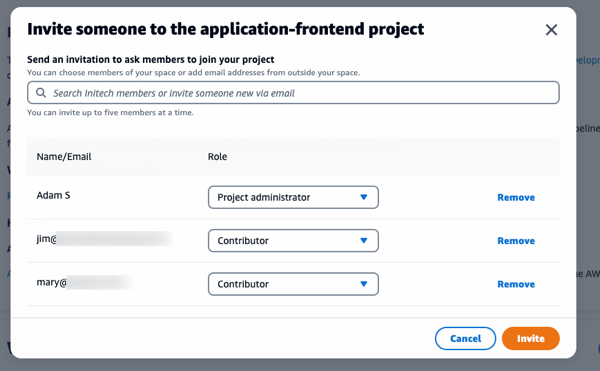
Each will receive an invitation email containing a link titled Accept Invitation, which when clicked, opens a browser tab to sign in. Once signed in, they can view all the projects in the Amazon CodeCatalyst space they’ve been invited to and can also quickly switch to other spaces in which they are the owner or to which they’ve been invited.
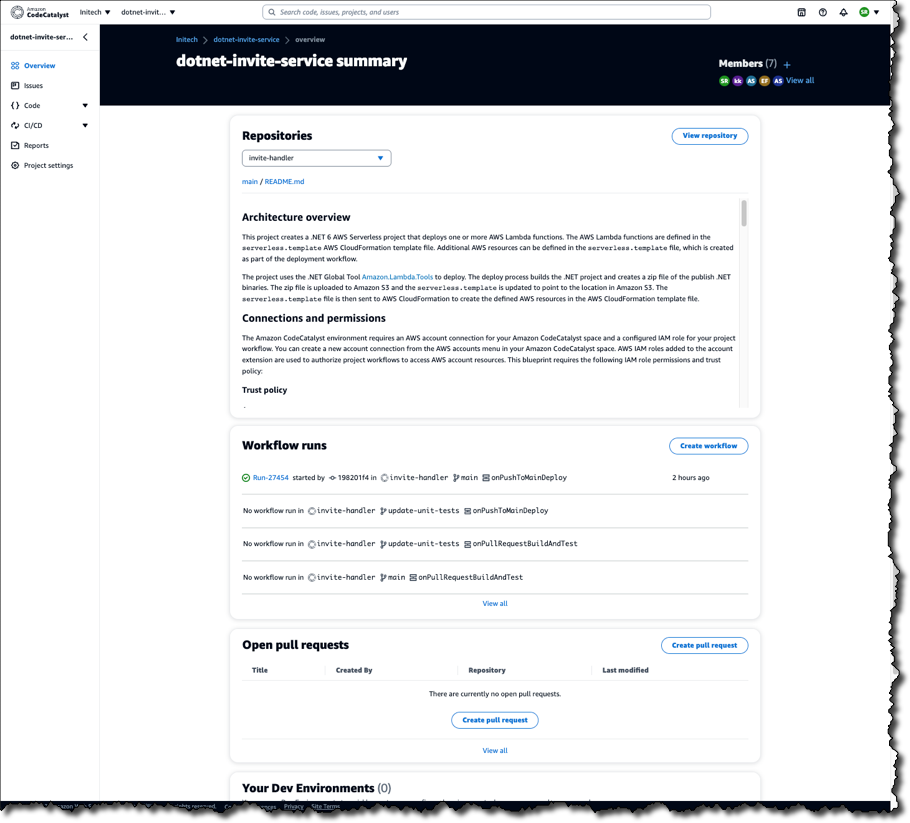
From there, they can select a project and get an immediate overview of where things stand, for example, the status of recent workflows, any open pull requests, and available Dev Environments.
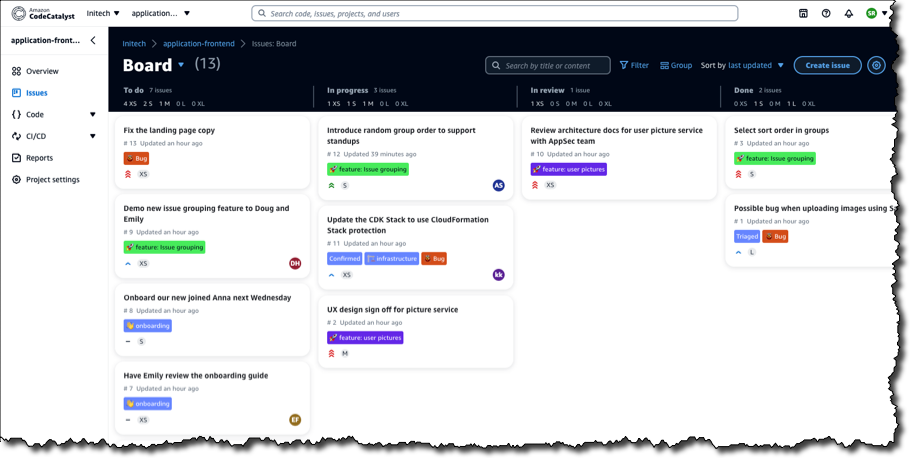
On the Issues board, team members can see which issues need to be worked on, select one, and get started.
Being able to immediately see the context for the project, and have access to on-demand cloud-based Dev Environments, all help with being able to start contributing more quickly, eliminating setup delays.
Get Started with Amazon CodeCatalyst in the Free Tier Today!
Blueprints to scaffold not just application code but also shared project resources supporting the development and deployment of applications, issue tracking, invite-by-email collaboration, automated workflows, and more are all available today in the newly released preview of Amazon CodeCatalyst to help accelerate your cloud development and delivery efforts. Learn more in the Amazon CodeCatalyst User Guide. And, as I mentioned earlier, additional blogs posts and other supporting content are planned by the team to dive into the range of features in more detail, so be sure to look out for them!